The Stateless Ethereum Book
What is Stateless Ethereum?
Stateless Ethereum is an update to the Ethereum protocol, in which blocks become self-contained units of execution. There is no longer a need to download the entire state of Ethereum, as all the required information is packaged inside the block.
Why is statelessness important?
Stateless Ethereum brings forth many scalability and usability features that the Ethereum community has been anticipating for a long time.
In practical terms, this means:
- Reduced validator hardware requirements: IO, disk space, and computation.
- As a result, a higher gas limit, since the lower gas limit was imposed by these hardware requirements.
- Faster sync times, as a node doesn’t need more than an EL block to join the network.
- Easy implementation of state expiry, a feature that has eluded Ethereum since before 2018.
- Trustless light clients that directly follow the chain without needing a third party to provide the state.
- Better decentralization, as it makes it possible to cheaply create private pools.
Main benefits
Statelessness in Ethereum brings significant benefits by addressing critical scalability and decentralization challenges.
Scalability
By removing the need for clients to store a large amount of data, validators can process more transactions per block, increasing throughput. Thus, we enable:
- Higher TPS, since the IO bottleneck is the principal hindrance to increasing the gas limit.
- No required synchronization, since all the data needed to execute a block is packaged with it.
- Reduced disk footprint, for non-block builders, validators, wallets, and simple nodes. In the case of verkle trees, block builders will also benefit from a reduced disk footprint.
Decentralization
By reducing the hardware requirements for validating nodes, it becomes feasible for more participants to run nodes on lightweight devices. This fosters decentralization by:
- Lowering entry barriers, where new roles with reduced hardware and monetary investments are created, allowing new actors to help secure some aspects of the network (see rainbow staking).
- Enabling users to create private staking pools, where hardware and monetary resources can be pooled collaboratively to participate in the network.
- Reducing the trust placed in centralized data providers, removing the need for lightweight clients to trust a centralized entity.
Innovative features
Statelessness also opens the door to innovative features, including:
- State expiry, which limits the size of the active state.
- Rainbow staking, which enhances flexibility in staking mechanisms by creating many niches for low-stake nodes to participate in the network’s security.
- Secure light clients, which is the consequence of not having to trust a centralized authority when using the blockchain.
Ease of use
Additionally, by reducing the state proof size, statelessness facilitates more seamless cross-chain communication, laying the groundwork for improved interoperability between the Ethereum L1 and its L2s.
Purpose of this book
This book is designed to serve as a comprehensive resource for understanding and contributing to our work on Stateless Ethereum.
Goals of This Book
- Explain the vision: Provide an in-depth explanation of the motivation behind Stateless Ethereum, including its potential impact on scalability and decentralization.
- Technical guidance: Offer clear and detailed instructions for developers, researchers, and contributors to engage with and extend our work.
- Knowledge sharing: Educate readers about various aspects of stateless block execution and their role in achieving Stateless Ethereum.
- Encourage collaboration: Foster a community of like-minded individuals by providing resources, tools, and best practices for collaborative development.
Who is this book for?
This book is intended for:
- Developers: Interested in contributing to the implementation of Stateless Ethereum.
- Researchers: Exploring the new designs enabled by Stateless Ethereum and learning how client architecture is impacted by these choices.
- Learners: Seeking to deepen their understanding of this major evolution of the Ethereum protocol.
Trees
Overview
Changing the state tree(s) is one of the core protocol changes we must make to achieve a stateless Ethereum future. The main goal is to design a new tree for more efficient state proofs.
Current tree
The current data structure used to store Ethereum state is a Merkle Patricia Trie (MPT). This article explains more about this tree.
Relevant design aspects
Let’s explore the most important angles on a new tree design, addressed in Verkle Trees and Binary Tree proposals.
Arity
The current MPT tree has an arity of 16. The original goal for this decision was to reduce disk lookups, as it means the tree becomes shallower compared to a lower-arity tree. The downside is that state proofs are much larger. For more details, read the following rationale section in the Binary Tree EIP.
Merkelization cryptographic hash function
The cryptographic hash function used for tree merkelization can significantly impact state-proof verification. Verifying state proofs involves calculating hashes in a specific way to compare against the expected tree root.
There are two performance aspects:
- Out of circuit: How fast it is to calculate the hash function result on a regular CPU.
- In circuit: How fast this can be calculated within a SNARK circuit under a particular proving system.
Both types of performance are relevant since the protocol requires calculating hash functions for different tasks both out and in circuits. The current tree uses keccak, which has good out-of-circuit performance but is challenging to perform efficiently on most bleeding-edge proving systems.
Account’s code
The current MPT doesn’t store the account’s code bytecode directly in the tree; it only stores a commitment (i.e., the code-hash as keccak(code_bytecode)).
While this decision helps avoid potentially bloating the state tree with all the accounts’ code, it has an unfortunate drawback: since the tree stores the result of hashing the whole code, we still need to provide the full code as part of the proof if we want to prove a small slice of it.
This is the reason for the worst-case scenario of proving the state for an L1 block. You can craft a block that forces the prover to include a contract code of maximum size. A better tree design should allow for more efficient proofing of account code slices.
Proving parts of an account’s code is critical to efficiently allow stateless clients or block state proofs. During a transaction execution, only a small fraction of an account’s code is typically executed. Think, for example, of an ERC-20: the sender will execute the transfer method but never call other methods like balanceOf on-chain.
Proposed tree strategies
The new tree proposals address these problems by proposing:
- A more efficient encoding of data inside the tree.
- Including the account’s code inside the tree, allowing size-efficient partial code proving.
- A more convenient merkelization strategy to generate and verify proofs more efficiently.
Verkle and Binary trees share the same strategy for solving the first two points — we’ll dive deeper into them on the Data encoding page. Each proposes a different strategy for the last point, explained in their respective Verkle Trees and Binary Tree pages.
Data encoding
Overview
How the Ethereum state is encoded into the tree can significantly impact data inclusion and updating, proof generation, verification, and size. Verkle and Binary Trees share a new way of encoding the data into the tree, so we’ll explore more on this page.
Code-chunking
In the parent chapter, we mentioned that we need an efficient way of proving slices of any account code. The current proposal encodes the account code bytecode directly in the tree, compared to only storing the code hash as done today.
For key design simplicity, the tree leaves hold 32-byte blobs, which means we need a way to break down account code into 32-byte chunks. Although the most natural approach is partitioning the code into 32-byte chunks and storing it in the tree under some defined tree key mapping for each code chunk, this isn’t enough.
The reason is that there are EVM instructions, i.e., JUMP and JUMPI, whose arguments contain an arbitrary offset to jump. For the jump to be valid, the target location must be a JUMPDEST opcode (0x5B). Today, EL clients do a JUMPDEST analysis to detect all valid jump destinations in existing code — this analysis requires full code access to detect which bytes are JUMPDEST instructions.
In a stateless world, clients only have partial access to code, so they can’t do a complete JUMPDEST analysis. For example, an account code has an instruction PUSH5 0x00115B3344, which maps to bytecode 0x6400115B3344. If a JUMP(I) instruction jumps to the fourth opcode, you might think this is valid since it’s a 0x5B, but this byte corresponds to the data of PUSH5, not a valid JUMPDEST. A stateless client must be sure which 0x5B bytes correspond to real JUMPDEST to perform JUMP(I) validations without requiring all the account’s code.
This means that the code chunkification strategy should not only slice the account’s code into 32-byte chunks but also in a way that allows an EVM interpreter receiving these chunks to detect invalid JUMP(I) instructions.
In the 31-byte code chunker page, we explore the currently proposed code chunker in more detail. This book will soon include other proposal candidates for code chunkers, so watch for updates!
It’s worth noting that if the EOF upgrade is deployed to the mainnet, the problem of invalid jumps would be solved for contracts using this format. This doesn’t mean we can completely forget about it since only newly created EOF contracts could avoid this problem, but we still have to support legacy contracts probably forever.
Grouping
If we think carefully about how usual EVM code is executed in blocks, we can note two facts:
- Accounts’ basic data, such as nonce and balance, are usually accessed together.
- Whenever a storage slot
Ais accessed, there’s a high probability that nearby storage slots are also accessed. - Although code execution isn’t perfectly linear, if we execute code chunk
A, there’s a high chance we’ll execute code chunkA+1.
In other words, state access during a block execution isn’t random.
This is an optimization opportunity since if we group states frequently accessed together in the same tree branch, proving the whole state requires fewer tree branches, making the state-proof size smaller.
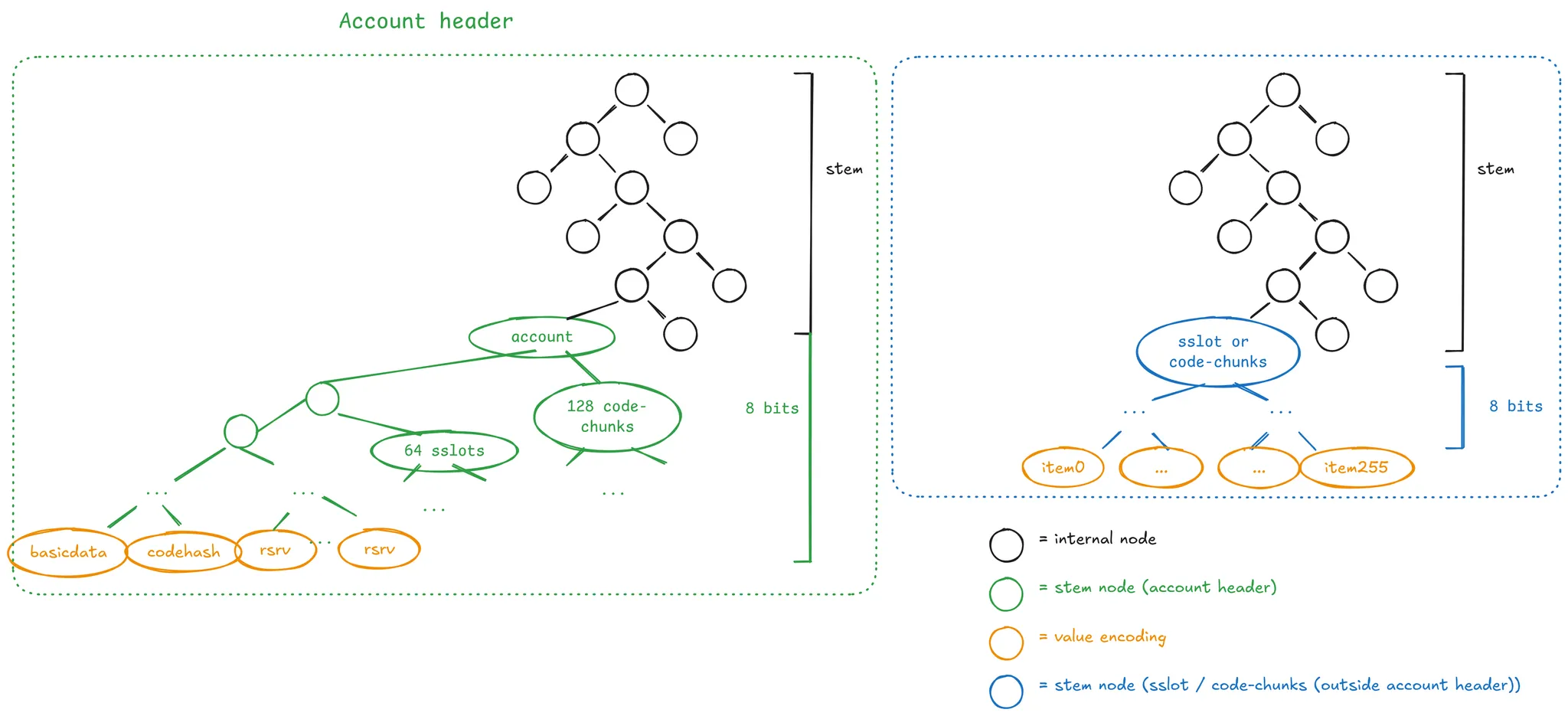
The current proposal is creating groups of 256 leaves, which can be depicted in the following diagram:
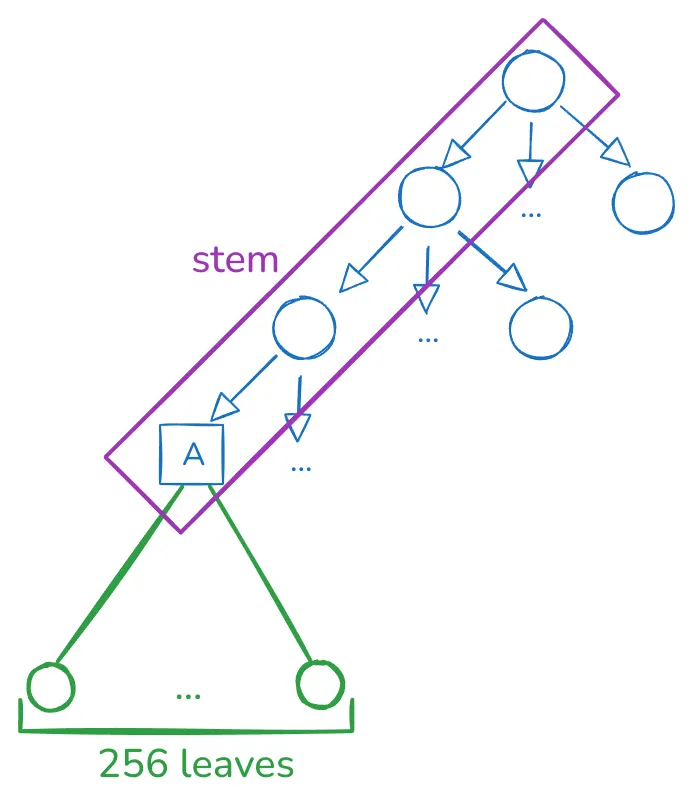
Please don’t focus on the tree arity since this will depend on the underlying tree design. The main point is that given a stem, we encode 256 leaves in that single branch, and we expect these values to have a high probability of being accessed together. Choosing a size of 256 is entirely arbitrary, but for historical reasons rooted in Verkle Trees proving efficiency. For Binary Trees, there’s more flexibility in choosing a different size.
Note that these 256 values can contain any arbitrary data. The current proposal has the following stem types:
- An account stem contains:
- One leaf encodes the nonce, balance, and code size.
- One leaf encodes the code hash.
- 64 leaves being the first 64 storage slots.
- 128 leaves being the first 128 code chunks.
- The unused leaves are reserved for potential future use.
- An account storage stem contains 256 consecutive storage slots for an account, excluding the first 64 storage slots that live in the account stem.
- An account code stem contains 256 consecutive code chunks of the account’s code, excluding the first 128 code chunks that live in the account stem.
Each account property (nonce, balance, etc.), storage slot, and code-chunk grouping is done by defining a proper tree key mapping. The way this is done depends on the specific tree proposal. Still, the general strategy is defining a function that generates the first 31 bytes for the 32-byte tree key, defining the stem, and the last byte indicates which of the 256 leaves corresponds to the required data.
For example, as mentioned in the above bullets, the storage slots 3 and 4 live in the account stem. The account stem defines the first 31 bytes of the tree key, so both storage slots share this byte prefix. Their last tree-key byte is HEADER_STORAGE_OFFSET+3 and HEADER_STORAGE_OFFSET+4, respectively. HEADER_STORAGE_OFFSET currently is 64, meaning in the group of size 256, we store the first 64 slots at offset 64.
31-byte code-chunker
Background reading
To get a proper background on where this code chunker fits into stateless Ethereum, read the Trees introductory chapter and the Code chunking section of Data encoding.
How does it work?
Let’s look at the following example code:
PUSH1 0x42 # 6042
PUSH1 0x00 # 6000
MSTORE # 52
PUSH2 0x0001 # 610001
PUSH2 0x0002 # 610002
ADD # 01
MSTORE # 52
PUSH20 0x0000000000000011223344556677889900115b33 # 73<...>
RETURN # F#
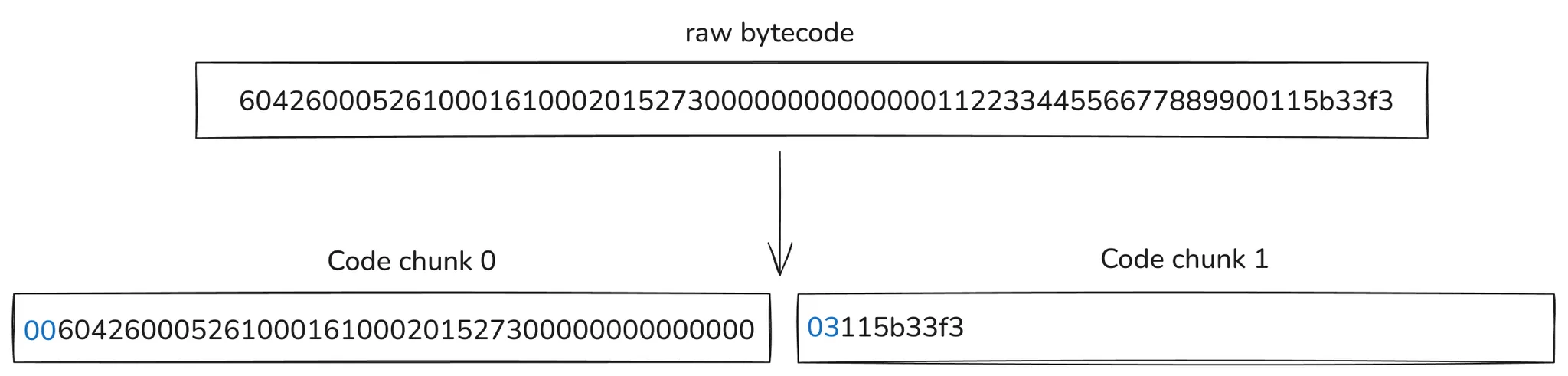
The following diagram shows how the code is chunkified:
Recall that an account code is a blob of bytes containing all the contract instructions. The goal of the code chunker is to:
- Output a list of 32-byte blobs, which will be stored as tree leaves.
- Given a code chunk without any extra information, an EVM interpreter should be able to detect if a JUMP to any byte in this chunk is valid.
Requirement 1 is easy to understand since each tree leaf stores 32-byte blobs. We can appreciate this requirement being fulfilled since the presented Python code returns a Sequence[bytes32].
Requirement 2 emerges from the fact explained in the Code chunking section in the current chapter. Since any JUMP(I) can jump to any byte offset in any chunk, an EVM interpreter should be able to detect if this jump is (in)valid without any further information than the code chunk itself.
The way the 31-byte code chunker resolves this is as follows:
- The account bytecode is partitioned into slices of 31 bytes in size.
- The first byte contains the number of bytes starting from the 31-byte slice that account for PUSHDATA, i.e., a previous
PUSH(N)instruction data.
In the diagram, this first byte is shown in blue. Note that the second code chunk indicates that the first 3 bytes correspond to the previous PUSH20 instruction. This allows the stateless client to note that the 0x5b byte in this code chunk isn’t a valid JUMPDEST!
Using this 1-byte information at the start of the code chunk allows the EVM interpreter to detect if any jump to an offset in the code chunk is valid, i.e., 0x5B is an actual JUMPDEST. Given that the bytecode length of a contract is N bytes, we know that the number of required chunks is ceil(N/31). If you’re interested in a Python implementation of the chunker, see the second code snippet here.
The design of this code chunker is very simple, but the encoding efficiency is not optimal. For example, if a bytecode doesn’t contain any PUSH(N) instruction, then we know any JUMP(I) is valid, but we’re still only encoding 31 bytes of actual code in 32-byte code chunks. Similarly, if this is an EOF contract, by construction, we know all jumps are valid; thus, we don’t require the extra byte. Soon, we’ll describe other code chunkers with different tradeoffs.
32-byte code-chunker
Background reading
To get a proper background on where this code chunker fits into stateless Ethereum, read the Trees introductory chapter and the Code chunking section of Data encoding.
How does it work?
This approach aims to store code in full 32-byte chunks while efficiently encoding the necessary metadata to validate jump destinations. This proposal contrasts with the 31-byte chunker by storing metadata separately rather than prepending it to each chunk.
The goals remain similar:
- Output the code itself as a list of 32-byte blobs (chunks), which will be stored as tree leaves.
- Provide a mechanism, using separate metadata, for an EVM interpreter to detect if a
JUMP(I)to any byte offset is valid (i.e., targets aJUMPDESTopcode and not PUSHDATA).
Instead of adding metadata to every chunk, the “Dense Encoding” variant method focuses only on potential ambiguities:
- The account bytecode is partitioned into full 32-byte chunks.
- We identify only the chunks that contain invalid jump destinations. An invalid jump destination is a
0x5bbyte that occurs within the data part of a PUSH instruction. - A map
invalid_jumpdests[chunk_index] = first_instruction_offsetis created. first_instruction_offset indicates the offset within the chunk where the first actual instruction begins. - This map is then encoded very efficiently using a Variable Length Quantity (VLQ) scheme (specifically, LEB128) applied to a combined value representing the distance between invalid chunks and the first_instruction_offset.
- This densely encoded metadata is stored probably prepended as a custom table for legacy contracts, i.e., before the actual originalbytecodes. EOF contracts can’t have invalid jumps since this is validated at deployment time.
Runtime usage
When a JUMP(I) occurs:
- The EVM checks if the target byte offset contains the
JUMPDEST(0x5b) opcode. - If the chunk index is not in the
invalid_jumpdestsmap, the jump is valid (assuming step 1 passed). If it is present in the map, the EVM must perform a quick analysis of that specific chunk, using the associatedfirst_instruction_offsetfrom the map, to parse the instructions within the chunk and confirm whether the target 0x5b is indeed aJUMPDESTopcode and not part of PUSHDATA.
Efficiency
This method leverages the observation that invalid jumpdests are rare in typical contracts. The code itself is stored in full 32-byte chunks (ceil(N/32) chunks for code length N). The metadata overhead is very low on average (~0.1%) and has a worst-case overhead of 3.1% (if every chunk contained an invalid JUMPDEST). For example, for contract size limits of 24KiB, 64KiB and 256KiB the maximum table overhead would require 24, 64 and 256 code-chunks respectively, assuming a best case table encoding of 1 byte per entry. Note that after 128KiB the table won’t fit into the 128 code-chunks reserved in the account header.
Implementations
For a Python implementation, you can refer to the spec. There is also a Go implementation.
Verkle Tree
Overview
Verkle Trees were the first tree design considered a viable solution for stateless Ethereum. The roots of this idea are in a paper published by John Kuszmaul. This idea superseded older Binary Tree approaches from years ago when SNARK proofs were still sci-fi technology.
Due to advancements in SNARK proving systems performance and concerns about quantum risks, Verkle Trees are increasingly likely to be superseded by Binary Trees. While a final decision has not been made, the community is moving in that direction.
Role of vector commitments in the design
At the core of Verkle Trees’ design is the use of a cryptographic component named vector commitment.
Without getting into formal definitions, this construct allows us to fill a vector with a fixed size N and:
- Compute a commitment to the vector, a succinct fingerprint of its contents.
- Given the commitment, we can efficiently generate a small proof to prove that a particular entry in the vector has a defined value.
- For Verkle Trees,
N = 256for proof efficiency reasons.
This construct addresses a fundamental problem with high-arity trees, such as the current Merkle Patricia Trie (MPT). For an MPT Merkle proof, each internal node in a branch must provide 15 siblings so the verifier can calculate the corresponding hash, verifying all the branches chain up to the root. This means the arity is a significant amplification factor for the proof size.
If we instead use vector commitments to represent child commitments, the construct allows us to generate proof only for the required children. Said differently, the proof size isn’t linear to the vector length.
The cryptography around the vector commitments is based on Inner Product Arguments and Multiproofs. This construction allows the generation of proofs without trusted setups and aggregates multiple vector openings into a single proof. This means that if we need to prove the openings of multiple vectors at different positions, we can generate a unique short proof of all those openings. This is precisely what we need for state proofs in this tree since proving a branch means doing one opening per internal node in the branch to connect all the vector openings up to the expected root.
Tree design
A tree key is still a 32-byte blob. The first 31 bytes define what’s called a stem. A stem decides the main branch from which all 256 values for that stem will reside. Note that the last byte of the tree key defines exactly 256 values; thus, we can conclude that the first 31 bytes define the tree key path, and the last byte defines which bucket from the 256 items contains the value.
Let’s look at the following diagram to understand how the stem maps to the tree path:
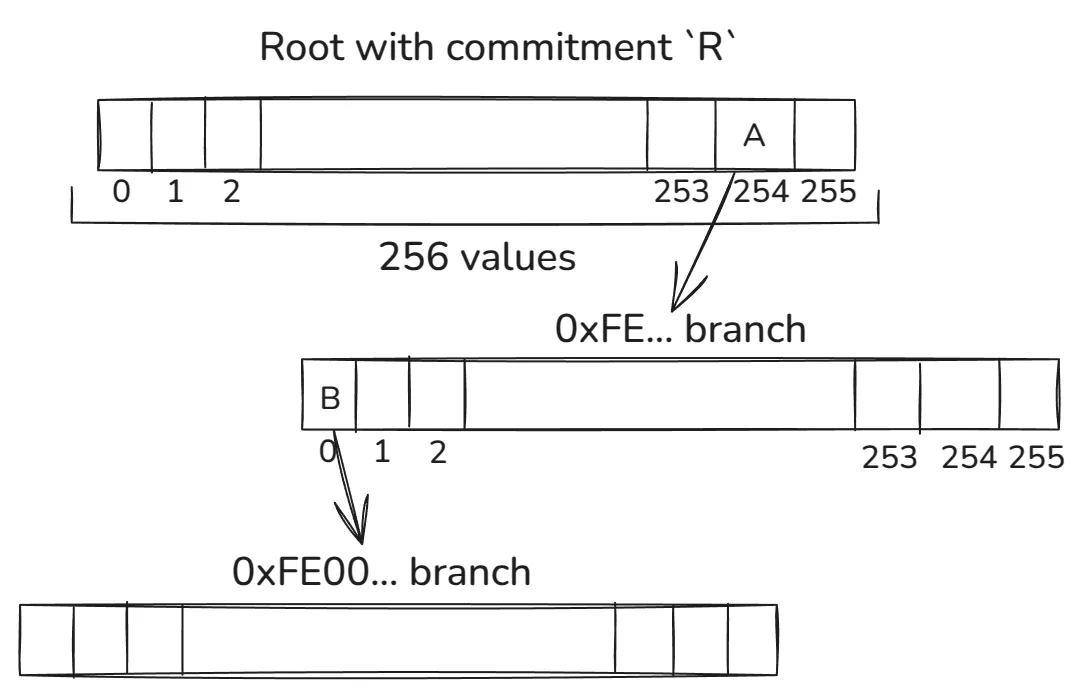
Each byte of the stem defines which item from each internal node from each level is used to walk down the path. This is shown by the 0xFE... and 0xFE00... examples depending on which path we use to walk down the tree. The A and B are vector commitments to the corresponding pointed vectors.
Given a stem, we always walk downstream until we reach a point where no other stem exists in the corresponding sub-tree. At this point, we insert the leaf node for the stem.
Continuing with our example, we see that after the first two levels, we reached an extension node:
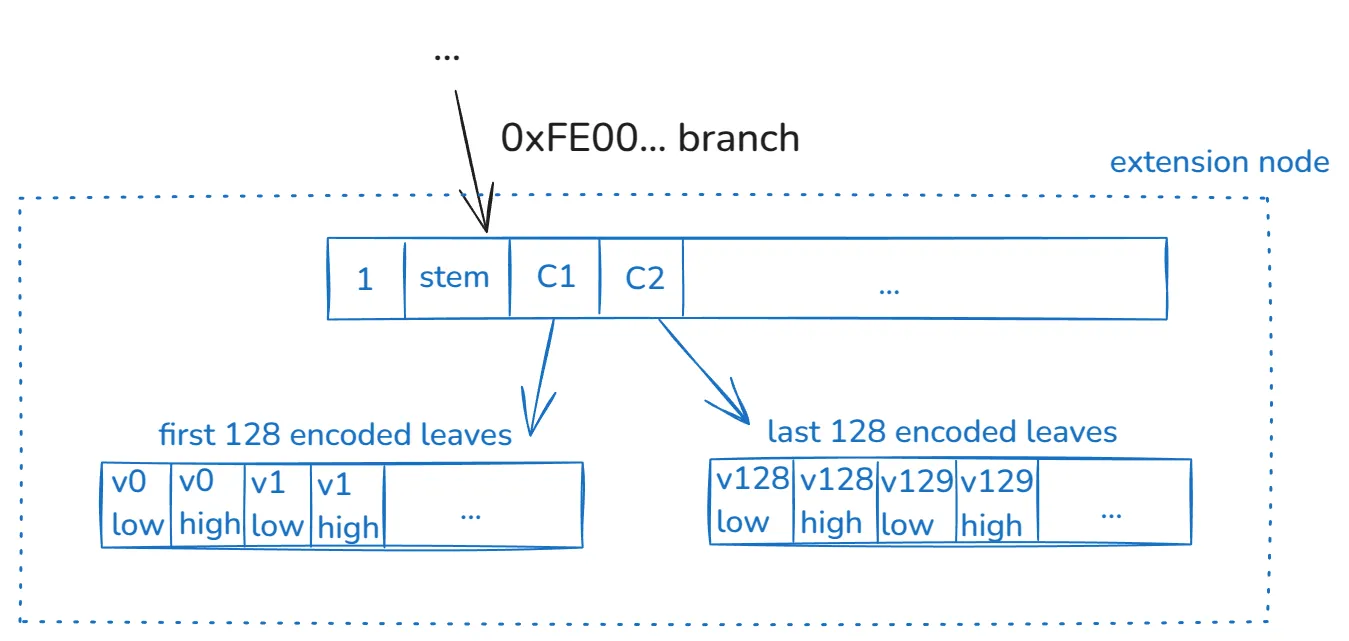
This construct (extension node) encodes the 256 values of the stem. As previously mentioned, in this example, no other stems exist in the tree with the prefix 0xFE00— if that were the case, we’d have more internal nodes branching the tree.
This extension node is constructed in the following way:
- As usual, a 256 vector with the first 4-items encoding:
- The value
1to prove this vector corresponds to an extension node. - The
stemvalue. Recall that the path can’t fully describe this value. C1andC2, which are commitments to two vectors.
- The value
- A 256 vector encoding the first 128 values of this stem. Each value is represented in two items. The commitment of this vector is the
C1mentioned above. - An analogous 256-vector mentioned in the previous bullet, but for the last 128 values of this stem, which has commitment
C2.
The main reason why we need to encode each 32-byte value in two buckets is related to the vector commitment construct. Each item in the vector is a scalar field element of a defined elliptic curve. This scalar field size is less than 256 bits. Thus, we need two finite field elements to encode a 32-byte value. Encoding also has a further rule distinguishing between written zeros and empty values.
We suggest reading this article to understand other details about the design.
Proof Construction
This section provides a high-level overview of how the proof is constructed.
At a high level, a block execution requires proving a set of key values from the tree so a stateless client can re-execute the block. Each key-value corresponds to a branch and a particular item in its corresponding extension node. Multiple key values might share the same main branch (i.e., stem).
The proof needs to do each corresponding vector opening from the extension node up to the tree root. In our example above, if we want to prove v1 value, we’d have to do the following openings:
- For
C1at position 2 proving has valuev1_low. - For
C1at position 3 proving has valuev1_high. - For
Bat position 0 proving has value1. - For
Bat position 1 proving has valuestem. - For
Bat position 2 proving has valueC1(note that openingC2is not needed!). - For
Aat position 0 proving has valueB. - For
Rat position 254 proving has valueB.
Given the list of key values to prove, many might share openings that are only done once. The proof contains extra information to decide how the verifier should expect each stem to map to tree branches.
Note that the prover does not provide R since it’s known to the verifier, i.e., it is the state root of the tree. As mentioned before, all these vector openings are batched in a single proof, which compresses all the openings in a single short proof.
We recommend reading this article if you want a more in-depth explanation of proof construction.
Binary Tree
Note: The following explanation is based on a recent proposal from Binary Trees. The design is expected to change as more people from the community provide feedback.
Overview
Using Binary Trees for the state tree is not a new idea. Back in 2020, this idea was explored in EIP-3102. Then, SNARKs were still in the early stages, and soon after, Verkle Trees became a more promising approach, so this direction was abandoned.
Many years have passed, and around mid-2024, two main motivations started to reignite the possibility of reconsidering Binary Trees compared to Verkle Trees.
The first one was some breakthroughs in quantum computers, which raised the concern that they could be a potential risk in 10 or 15 years. There’s no consensus around interpreting recent events, so there’s still the possibility that they will take many more years or never be a real risk for elliptic curve cryptography. Depending on how conservative core developers want to be, this might be a significant decision factor. Also note that if Verkle Trees are deployed, at least one extra state tree conversion is guaranteed to happen.
The second one is the rapid pace of improvement of SNARK/STARK proving systems. The speed at which they can provide proving throughput for hashes has been improving rapidly without requiring absurd hardware specs. Depending on the hash function used, the proving performance is or isn’t enough for L1 needs — we’ll dive more into this later.
In summary, a Binary Tree construction is now again a potential option for a SNARK-friendly state tree with other tradeoffs compared with the Verkle Tree.
Tree design
The currently proposed EIP-7864 pulls many ideas from EIP-6800, which are still helpful. These include many of the desired properties described in the Data Encoding page.
The tree construction is more straightforward than Verkle Trees since it relies only on a hash function for merkelization. The arity of the tree is defined as two since this arity minimizes the proof sizes. To learn more details, refer to the corresponding rationale section of the EIP.
Given a tree key, we define the first 31-bytes as the stem. This stem defines the main path where the 256 values are determined by the last byte of the tree key. This is better described by the diagram presented in the EIP:
Given a tree key value to be inserted:
- With the first 31-bytes, we walk the black nodes (i.e., internal nodes). Starting with the most significant bit, each bit walks the tree downstream from the root.
- When we reach an internal node representing an empty subtree, we insert the leaf-level subtree, a full Merkle tree with 256 leaves. Said differently, the 256 values for this stem are a full tree with 8 levels.
- Depending on the last byte of the tree key, we store the desired value in the corresponding leaf.
This idea is the same as Verkle Trees, where each stem stores 256 values corresponding to the last byte of the tree key. Instead of using vector commitments, we use a full Merkle tree as a form of vector commitment.
The tree is merkelized using a hash function which allows us to hash 32-bytes -> 32-bytes and (32-bytes, 32-bytes) -> 32-bytes. Any secure hash function can be used with this construction. The current EIP proposed Blake3 as a conservative one, but this isn’t fully decided—more about it in the next section.
Proof Construction
If we need to build a Binary Tree proof for a list of key values, we have two options:
- Build a usual Merkle Tree. This is not different from how you can build proofs in the current Merkle Patricia Tree. The construction will be much more straightforward, i.e., we don’t have accounts and storage tries but a unified state tree, no RLP is used for encoding nodes data, etc. Also, the arity of the tree generates smaller proofs.
- For an L1 block required pre-state, a worst-case scenario still generates a tree proof that is bigger than desired. For these cases, we can create a SNARK/STARK proof, which is a Merkle Proof verifier in a proven circuit. This requires more work to generate, but the proof is smaller.
Hash function for merkelization
When using SNARKS/STARKs to generate a state-proof check, the proving performance is heavily influenced by the hash function used for merkelization. Normal cryptographic hash functions such as Keccak and Blake3 aren’t designed to be efficiently proven in circuits. Other cryptographic hash functions, such as Posiedon2 (i.e., arithmetic hash functions), are specifically designed to be efficiently proven in SNARKs. Their main difference is that arithmetic hash functions don’t rely on bitwise operations but directly work on desired finite fields matching the underlying proving system.
The current proving performance on desired hardware specs for normal hash functions such as Keccak or Blake3 is still an order of magnitude slower than required for L1 blocks. Hence, we must wait for them to keep improving in performance or for them to need more powerful hardware for block builders.
However, if we have an arithmetic hash function such as Poseidon2, the current proving performance on target hardware is more than enough for L1 block needs. The main drawback is that Poseidon2 is still not considered safe for use in L1. The Ethereum Foundation cryptography team has recently launched a public initiative to assess its security more formally. From another perspective, multiple zk-L2 have been using Poseidon for some years, which indirectly means billions of dollars publicly at stake — while this isn’t a formal bug bounty program, any black hat hacker that knows how to break the hash function could already attack these networks. This doesn’t prove Poseidon is safe, but it gives an optimistic perspective while the formal assessment is done.
Ideally, the Binary Tree should use Poseidon2 since it offers the best-proving performance. This allows block builders to have lower hardware specs, which is good for decentralization. Moreover, it’s crucial that proving the hash function doesn’t get in the way of bumping the block gas limit to keep improving L1 scaling. Hopefully, protocol developers can make a final call on this front within the next year.
BLOCKHASH state
Motivation
In a stateless Ethereum world, we require that a block provides only the data needed for its execution, compared to today’s reality of forcing the clients to store the whole state. This applies not only to plain re-execution but also to SNARK proofs.
Usually, all the required state for executing EVM instructions rely on data stored in the state tree. For example, CALL, BALANCE, SLOAD, and EXTCODEHASH always involve reading the state to resolve their execution. Since this data lives in a merkelized tree, we can generate state proofs to provide this data trustlessly.
There’s a particular exception for BLOCKHASH. Before the Pectra update (planned for Q2 2025), executing BLOCKHASH relied on information not stored in the tree. This meant that execution clients must store the last 256 block hashes in a separate storage. This isn’t a big ask since full nodes store the whole blockchain anyway, so accessing this information was easy. While the blockchain is a merkelized structure, and you could provide proof for the block hashes, this would require up to 256 block headers for the evidence, which is prohibitive.
Setting up the stage…
In Pectra, the protocol took an important step towards fixing this problem by delivering EIP-2935. This EIP adds a new rule to the protocol where each new block includes the previous block hash in a system contract.
This means that BLOCKHASH can now be resolved from the state tree, as all other EVM instructions do. EIP-2935 doesn’t force BLOCKHASH to use the state tree, so clients shouldn’t change how they execute BLOCKHASH.
Fixing the last missing piece…
The last required change is finally requiring BLOCKHASH to be resolved from the state tree rather than from the blockchain. This is where EIP-7709 comes into play.
The change is quite simple. BLOCKHASH now involves a state tree access, which can be done by reading the corresponding storage slot from the EIP-2935 contract. This implies that the gas cost for the instruction should now map to an equivalent SLOAD.
Backward compatibility
Despite EIP-2935 storing 8191 historical block hashes, the BLOCKHASH instruction only serves the last 256 values. This is required to avoid a breaking change in the instruction semantics (i.e., current BLOCKHASH executions asking for older values must still return 0).
Gas cost remodeling
Recommended reading
It’s highly recommended that you read the Trees chapter and Data encoding page since those changes are fundamental to the need for a gas model reform.
How are costs related to stateless Ethereum?
As discussed in other chapters, multiple protocol changes are needed to achieve Ethereum statelessness. Some of these changes must impact gas costs since they are profound changes that should reflect new CPU or bandwidth costs or mitigate new potential attack vectors.
Changing gas costs is always a complex problem since the gas cost model is part of the blockchain’s public API. Although the protocol can’t promise fixed gas costs forever, it’s usually something that we must think carefully about since it can break existing contracts that have baked-in assumptions. Not all gas cost changes are negative, but the overall impact (positive or negative) depends on each case.
What are the main drivers for gas cost changes?
The following are reasons that motivate doing a gas cost remodeling:
- The block will contain an execution witness that includes new information—at a minimum, it will contain proof. The block size is affected by EVM instructions, which depend on the state.
- The new trees have a new grouping strategy for storage slots, which attempts to lower the gas cost access.
- Code is also included in the tree, so gas must be charged to access it when contracts are executed.
The only EIP proposed to address these changes is EIP-4762, which is currently focused on the Verkle Trees as the new tree. For Binary Trees, the execution witness is not entirely clear today. The book will contain an explanation whenever the roadmap is clearer on this front, so stay tuned!
EIP-4762
Overview
This EIP can initially be intimidating, but the underlying principle is simple. Every direct or indirect state access required in a block execution must be included in the execution witness. Not doing so means that if a stateless client attempts to re-execute this block, it will be unable to do so due to a lack of information.
This EIP’s goal is to define new gas cost rules to account for:
- Chunkification of account properties (e.g., nonce, balance, code).
- Disincentivize growing the block execution witness.
- Avoid changing current costs as much as possible to limit UX impact.
A necessary clarification is that this EIP is currently designed for the Verkle Trees proposal.
Dimensions of gas cost changes
Let’s look at the different dimensions of gas cost changes.
EVM instructions new gas costs
The following instructions have a new gas cost:
CALL,CALLCODE,DELEGATECALL,STATICCALL,CALLCODESELFDESTRUCTEXTCODESIZE,EXTCODECOPY,EXTCODEHASHCODECOPYBALANCESSLOAD,SSTORECREATE,CREATE2
These instructions share the common feature of accessing the state to perform their action; thus, their gas cost should reflect the new reality.
Let’s look at some examples:
BALANCE: when this instruction is executed, theBASIC_DATAleaf for the target address is accessed. This leaf should now be part of the witness.SLOAD: might be the most obvious example, since the target storage slot leaf will be included in the witness.EXTCODECOPY: recall that now the account code is part of the tree, so accessing the code of any account means state access, which is included in the witness.
Code execution
As explained in the Accounts code section of Trees chapter, account code is now part of the tree. This is required since stateless clients need the code to re-execute the block. Instead of providing all the account codes, we only need the code chunks effectively accessed during block execution (which is usually far less than the complete code).
The EVM interpreter must include any code chunk containing executed instructions to do this. Note that if two or more instructions from a given code chunk are executed, the code chunk is only included and charged once. The included code chunks aren’t always consecutive since instructions like JUMP or JUMPI can jump to a different code chunk.
Note that most opcodes only span a single byte of a code chunk, except instructions with immediates. For example, when executing a PUSH(N) instruction, we must account for 1+N bytes in the code since the immediate should also be included. This is important since a PUSH(N) corresponding bytecode could span multiple code chunks.
Out of gas and REVERT
It’s worth noting that if a transaction execution runs out of gas or executes a REVERT instruction, everything added to the witness isn’t removed. This should feel natural since when a stateless client re-executes the block, it still needs all the code chunks and state required to reach the reversion point.
Transaction preamble
In today’s rules, an intrinsic cost of 21_000 gas includes warming rules or particular accounts, such as the transaction origin. This is required since we have to validate that the transaction is valid by doing nonce and balance checks. All these implicit (or rather, included) accesses within the intrinsic cost are also included in the execution witness at today’s cost.
Contract creation
Creating a contract has some preliminary rules that must be enforced. For example, we must do a collision check on the new contract address since we can’t overwrite the existing contract code. This means the execution witness will include account field accesses since stateless clients require this data for validity checks.
Recall that the contract code is now stored in the tree. This means that the transaction that creates a contract now performs writes into the tree, which should be accounted for. The current gas rules indicate that 200 gas per contract byte should be charged — this rule has been removed and simplified to be considered a tree write. This new reality must be reflected in the gas costs.
Block-level operations
A block execution entails more actions than transaction execution. For example, staking withdrawals are operations done after the list of transactions is executed—these actions also perform read/write operations into the tree. These operations don’t have any gas cost, but they should still be accounted for as information to be included in the execution witness.
Precompiles & system contracts
Precompiles and system contracts have some exceptions to the rules described in this EIP.
Regarding precompiles, if we do a non-value bearing CALL to a precompile, we are not strictly required to include its BASIC_DATA, which contains the code size. Usually, the code size is needed so a stateless client can detect jumps beyond the contract size. But precompiles don’t have bytecode contracts, and we know their size is always 0.
We can look at an example of system contracts. By EIP-2935, a system contract stores the previous block’s hash. Although in the previous section, we mentioned that contract execution must include all code chunks, the bytecode for this system contract is defined at the spec level—stateless clients already have the contract’s bytecode, so we can avoid including it in the witness.
Access events
All the above rules are handled in a unified way via access events. Access events keep track of all state access (read/write) required during a block execution, which is needed for correctly charging the gas costs.
These are the relevant constants to understand how gas is charged:
WITNESS_BRANCH_COSTwhen a new tree branch has a read access for the first time.WITNESS_CHUNK_COSTwhen a specific leaf has a read access for the first time. Recall that tree branches contain 256 leaves.SUBTREE_EDIT_COSTwhen a branch must be updated. This means that at least one write was done in this branch leaves.CHUNK_EDIT_COSTwhen an existing leaf is overwritten with a new value.CHUNK_FILL_COSTwhen a non-existing leaf is written for the first time.
Every time a state read/write is included as an access event, we must check if the operation should charge each of the costs mentioned above. These costs are charged once per location, per transaction execution. For example:
- A second write to a storage slot only charges warm-cost since the branch and leaf inclusion were already charged on the first access.
- If the storage slot
0of a contract is accessed for the first time, onlyWITNESS_CHUNK_COSTis charged. Recall that the first 64 storage slots live in the same branch as accounts fields. Some form of “call” that started this contract code execution already paid forWITNESS_BRANCH_COST, so we only need to chargeWITNESS_CHUNK_COST. - When the first byte of a code-chunk is accessed, we charge
WITNESS_BRANCH_COST+WITNESS_CHUNK_COST. Access costs for the subsequent instructions executed in the same code chunk aren’t charged. When bytecode execution overflows into the next chunk in the same branch, onlyWITNESS_CHUNK_COSTis charged. And so on.
State conversion
Introduction
State conversion is an important and complex topic for a stateless Ethereum. As mentioned in the Trees chapter, one required protocol change is changing the tree used to store the Ethereum state. Although it is easy to spin up a new blockchain with a new shiny tree, life is more complicated when you need to do it with an existing tree storing a state of ~300GiB.
This chapter explains how the protocol will switch the state tree to the new target tree while attempting to run seamlessly, flawlessly, and safely with minimal user impact.
In sub-chapters, we dive deeper into explaining more low-level spec proposals on how this is done in more detail and intricacies. We suggest readers read sub-chapters in order since each will rely on a good understanding of the previous ones.
Motivation
To understand why we need to care about this problem, please read the Tree chapter of this book. Going forward, we only need to understand that a new tree should be used, and somehow, it has to be introduced into the protocol.
Today’s proposed strategy is converting the data with an Overlay Tree, which we explore in more detail in sub-chapters, but for now, let’s stick to the big picture.
Big picture
Here’s a summary of what we want to achieve:
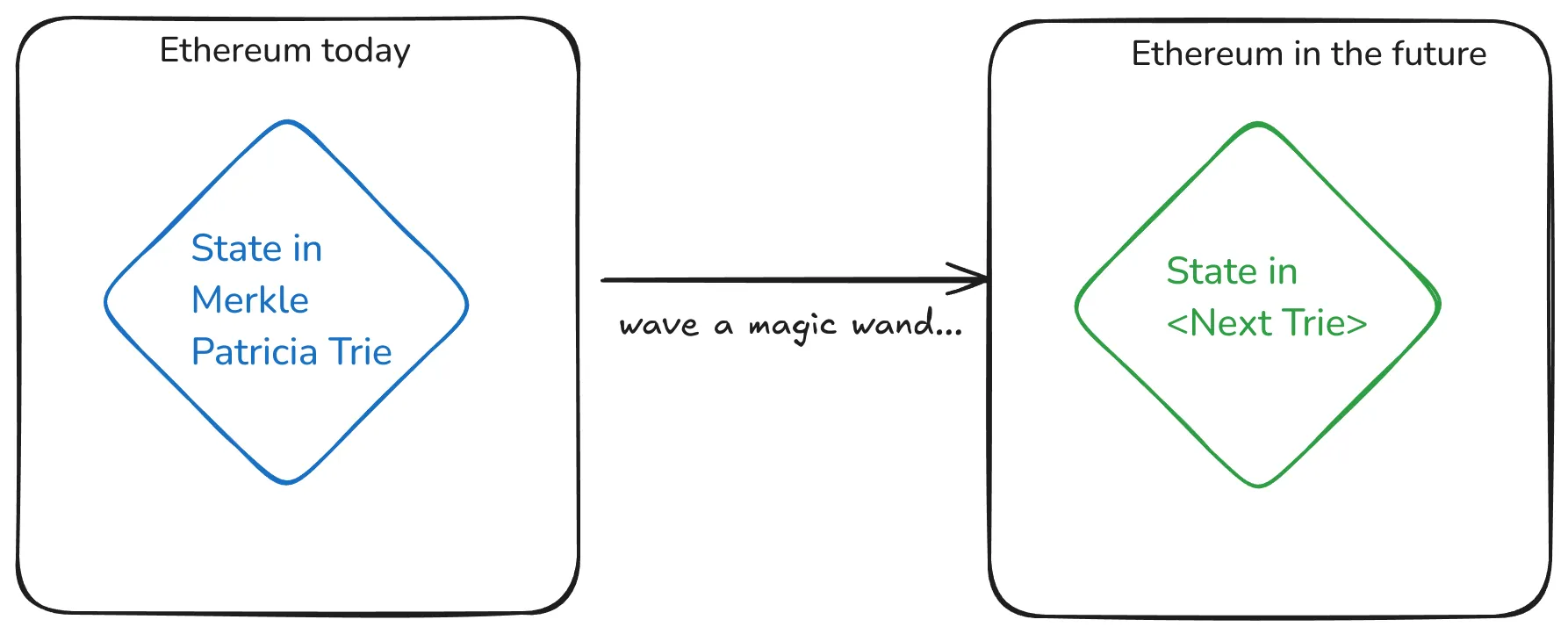
Unfortunately, we can’t wave a magic wand and call it a day, so the current proposal will go in two phases.
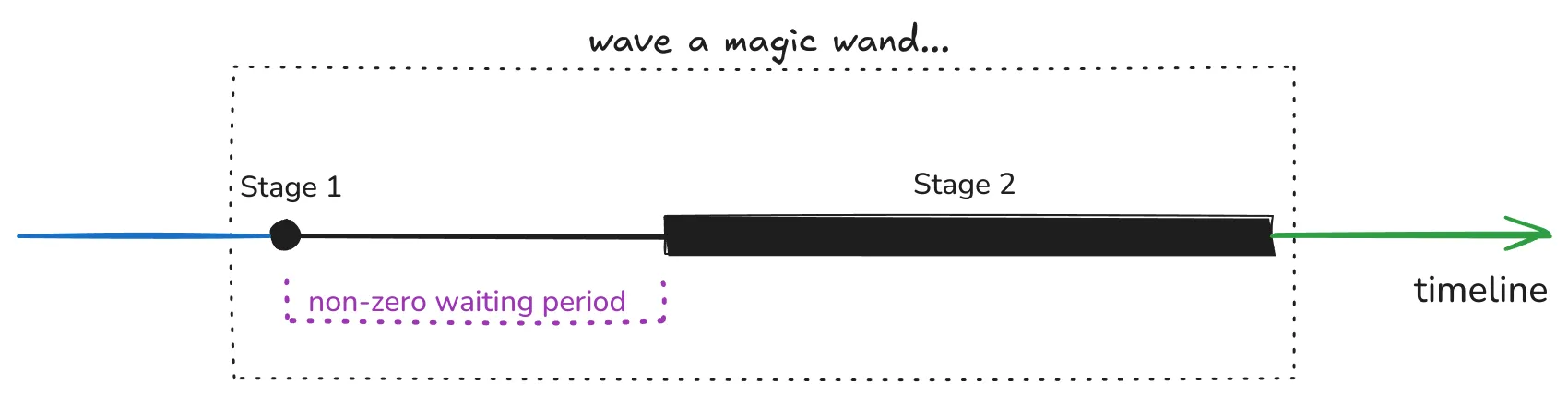
Note that these two phases will happen while the chain runs as usual, so we’re changing the system’s database while the system is running! Previous research has explored offline conversion methods with other tradeoffs and risks.
Stage 1 - Introduce the new tree
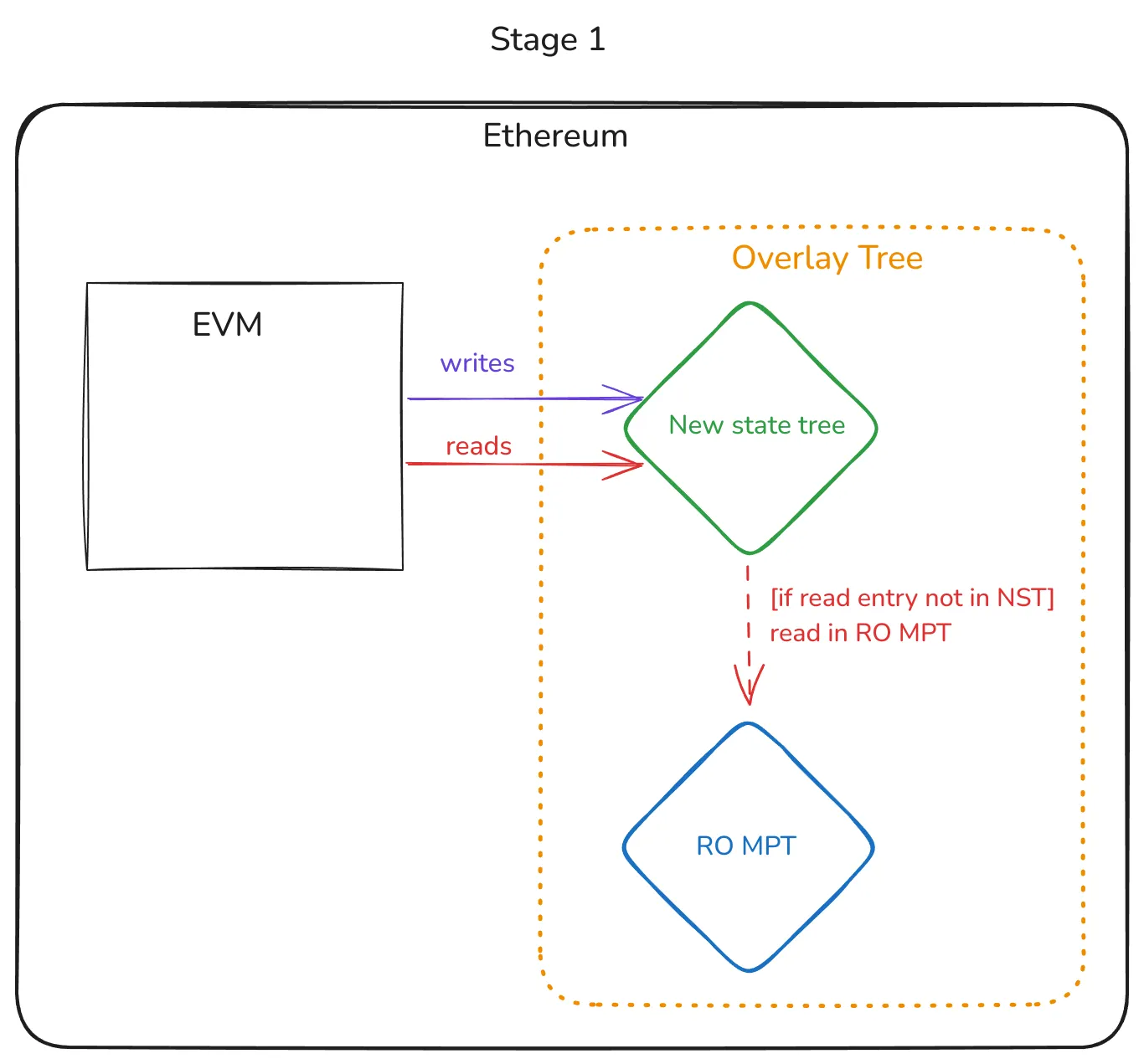
In Stage 1, a protocol change is activated (EIP-7612), which:
- Makes the MPT read-only (i.e., RO MPT).
- Introduces the new (empty) state tree.
- Any new write produced by executing transactions in a block is done in the new tree.
- Any read is first done in the new tree; if the key isn’t found, it is done in the RO MPT.
Note that in the timeline shown before, this stage 1 is a single point in the timeline. As soon as the timestamp activates EIP-7612, the goal of the EIP (i.e., introducing the new tree) is done. This EIP doesn’t deal with moving existing data, which is done by other EIPs, which we will explain soon.
We dive deeper into EIP-7612 in its corresponding sub-chapter.
Waiting period…
There is a required period after Stage 1 is activated before Stage 2 can be activated. The goal is for the RO MPT from Stage 1 to be final (i.e., the chain reaches finalization).
This is critical so no chain reorganization can mutate the RO MPT. Doing this greatly simplifies the implementation of EL clients since they know that not only is the MPT read-only but it’s completely frozen. Moreover, it simplifies the preimage generation and distribution tasks, but we expand on this later in the book.
Stage 2 - Move the existing data from the MPT to the new tree
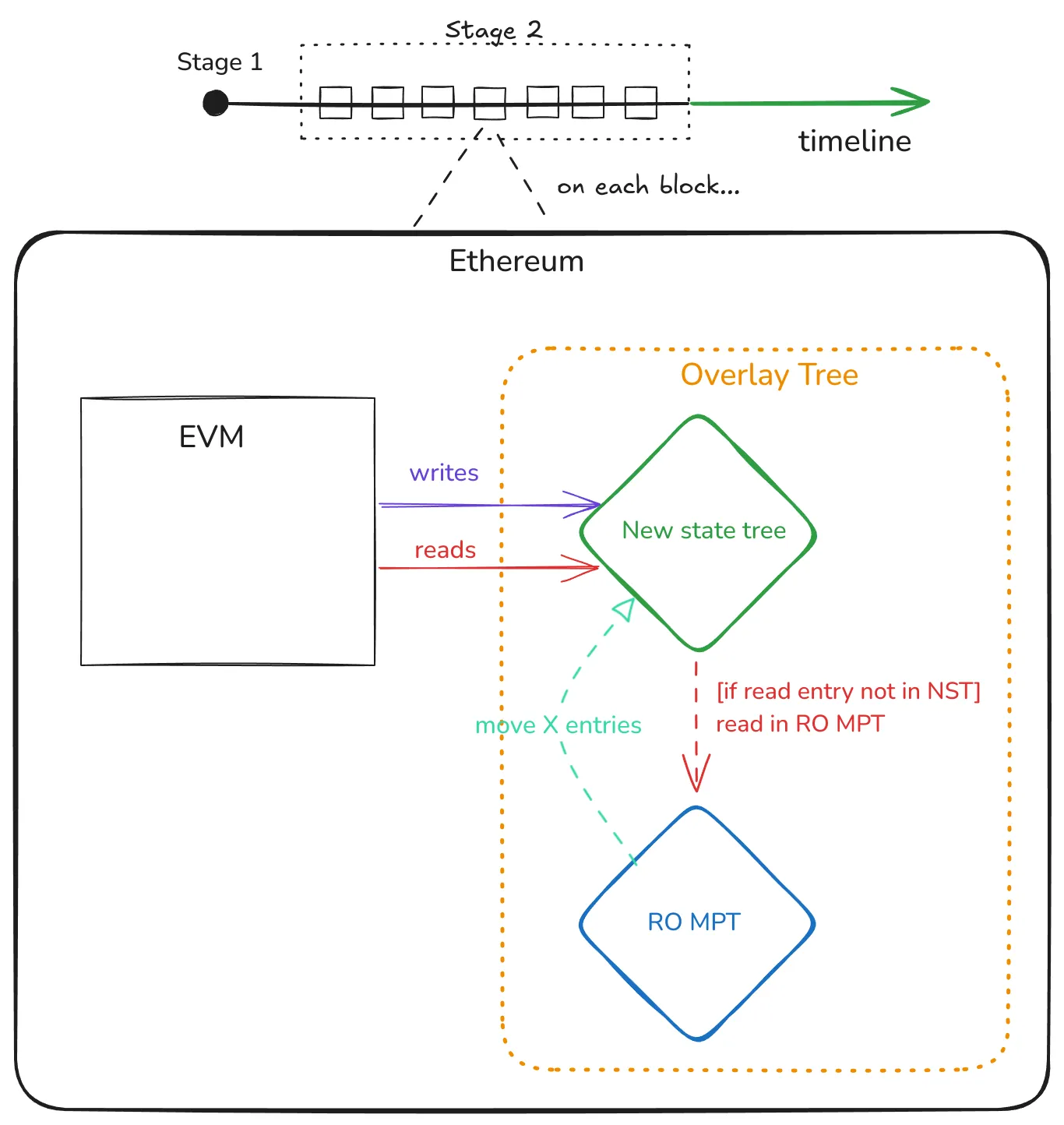
Let’s unpack what this stage is about:
- The functioning of the Ethereum chain continues to be as we described in Stage 1, with a (finalized!) RO MPT, and the new tree with the defined read/write rules.
- An extra rule is added: on every block, we move a defined (X) number of entries in the RO MPT to the new tree. This is when we start moving the data from the old to the new tree.
- Since the MPT is read-only and we always make progress on each block, we’ll eventually reach the end of the conversion.
Note that this is a high-level explanation of the idea; we’ll dive into how this works in the EIP-7748 sub-chapter.
How are contracts, clients, and users affected during this conversion phase?
This is an excellent and relevant question; we can separate it into multiple dimensions.
Users sending transactions
The state conversion doesn’t change how transactions are created and sent to the blockchain.
EVM contract execution
From the perspective of EVM execution, the state is accessed through usual opcodes without knowing where this is coming from or if data is being moved between trees in the background.
As explained in the EVM gas cost remodeling chapter, Stage 1 (EIP-7612) is bundled with EIP-4762, which changes gas costs which isn’t opaque to the EVM. However, note that these gas cost changes are unrelated to the state conversion but are using the new tree, so the state conversion per se isn’t related to this effect.
State proofs
Recall that we have three periods:
- Before Stage 1
- This is how the chain works today — proofs can be created with the known drawbacks as usual.
- Starting from Stage 1 and continuing until Stage 2 is finished.
- During this period, the chain uses the described Overlay Tree, which is composed of two trees. Creating state proofs during this period is very challenging. Given a key in the state, this key active value might be in the new tree or still in the RO MPT.
- A proof of absence for a key requires a proof of absence in both trees.
- A proof of value in the RO MPT requires a proof of absence in the new tree (i.e., prove that the value isn’t stale).
- The root of the RO MPT isn’t planned to be part of the block since the new state root will be the one from the new tree. This adds extra complexity to proof verification.
- During this period, the chain uses the described Overlay Tree, which is composed of two trees. Creating state proofs during this period is very challenging. Given a key in the state, this key active value might be in the new tree or still in the RO MPT.
- After Stage 2 is finished (i.e., conversion is over)
- We can leverage all the expected benefits:
- Smaller proofs.
- Faster generation and verification.
- Easily SNARKifiable.
- Single root for proving (i.e., the state lives in a unified tree, and not account+storage tries)
- We can leverage all the expected benefits:
Syncing
EL client syncing gets temporarily more complex while the state conversion is running. Since the state exists both in the RO MPT and the new tree, syncing both is required.
The RO MPT syncing has two potentially relevant sub-stages:
- Before RO MPT finalization, healing phases of snap sync are expected to be required.
- After RO MPT finalization, no healing phases are required. The finalized RO MPT root could be transformed into a flat-file state description that can be downloaded and reconstructed from the tree from the leaves.
The new tree will use whatever new syncing mechanism is designed for it.
Syncing isn’t a trivial topic, so more research and experimentation are required.
EIP-7612
Overview
Two EIPs are proposing a new tree to replace the Merkle Patricia Trie(s) (MPT). For more information, refer to EIP-6800 and EIP-7864.
The EIP-7612 describes the first step in this transition. Although its title mentions Verkle Trees, it can be applied to any target tree. It is also a stepping stone in a more general strategy for a full tree conversion.
This EIP approach is simple: introduce the empty new tree (Overlay tree) while keeping the existing MPTs, which are now read-only. This construction can be depicted as:
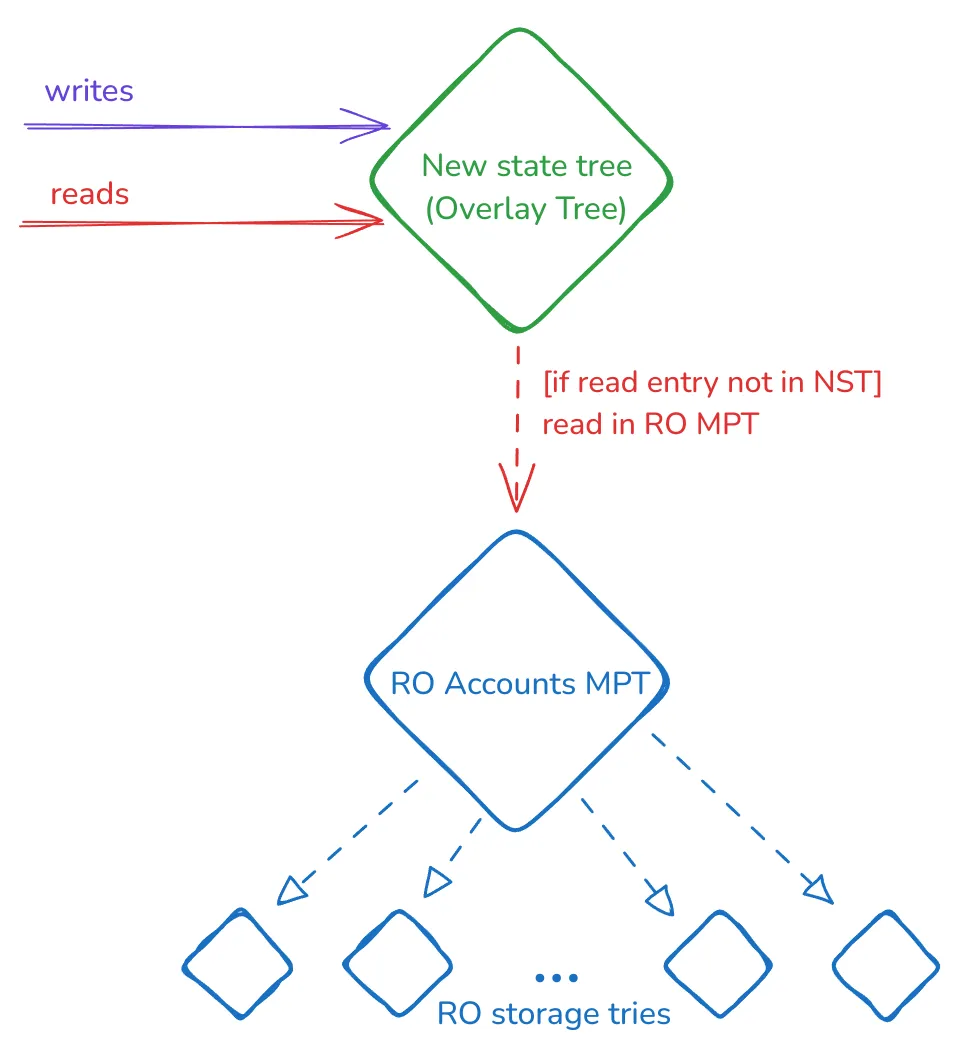
Read and write rules
When the EIP is activated (i.e., FORK_TIME), this Overlay Tree works in the following way:
- On a write operation for a key:
- Store it in the new tree.
- We don’t delete, update, or insert the key in the MPT, being the account or storage trie for an account. MPTs are read-only and can (and will) have missing or stale values.
- On a read operation for a key:
- Read the key in the new state tree:
- If the key exists, return its value. If it doesn’t, move to the next step.
- Read in the corresponding account/storage trie and return the result.
- Read the key in the new state tree:
Block state root
For all the blocks after the EIP activation timestamp, the block state root is the root of the introduced tree. The read-only account MPT root won’t be part of the block, but since it’s read-only, we can assume its root is the latest block before EIP activation.
State proofs and syncing
Please refer to the corresponding sections in the State Conversion chapter: State Proofs and Syncing.
EIP-7748
Recommended background
We highly recommend reading the high-level explanation for state conversion in the State Conversion chapter and the EIP-7612 explanation.
Big picture
This conversion EIP can be compactly described as:
Starting at block with timestamp greater or equal to CONVERSION_START_TIMESTAMP, on every block migrate CONVERSION_STRIDE conversion units from the read-only MPTs to the active tree. Do this until no more conversion units are remaining.
To migrate the data from the MPT(s) to the new tree, a deterministic walk is done in the MPT(s), moving conversion units to the new tree. We’ll explain conversion units soon, but let’s focus only on the walking algorithm.
The walking algorithm is a depth-first walk, meaning that we walk the account’s MPT, and when a leaf is found, we do a depth-first walk into its storage trie (if not empty).
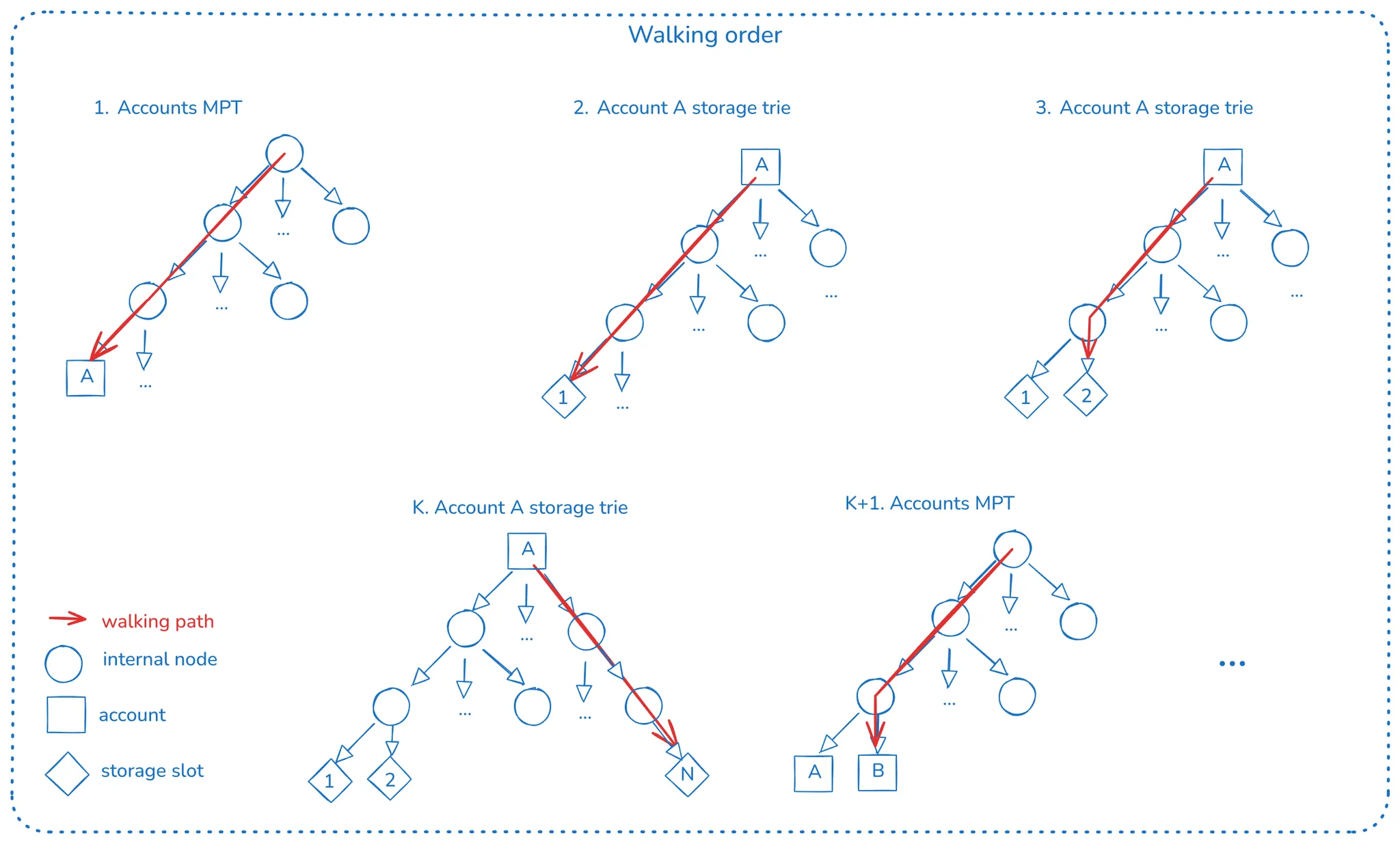
The above image summarizes how the walking is done:
- When we reach account A, we walk into its storage trie, copying all storage slots to the new tree.
- After finishing the storage trie walk, we copy
Account Adata (nonce, balance, and chunkified code). - We continue walking the account’s MPT, now standing on account B.
- We walk the storage trie (if any, since if B is an EOA, this tree is empty) and continue the process.
Since all the MPTs are read-only from the start of the conversion process, the walk is guaranteed to be complete, and thus, the conversion will finish.
This process of walking and copying is done within the block execution pipeline, where only CONVERSION_STRIDE items are copied to the new tree. The walk and copying continue to the next tree, so the whole copying process spans multiple blocks. This is done to put a bound on the overhead of state conversion per block.
CONVERSION_STRIDE value
Choosing the correct value for CONVERSION_STRIDE is important since each step of the walk implies:
- CPU overhead of re-hashing the corresponding key.
- IO overhead since we’re copying data to the new tree.
- CPU overhead is added to the block state root computation since the new tree has extra writes apart from the ones generated by the execution of the transactions.
Previously run proof of concepts done in Geth for Verkle Trees has shown that the CPU overhead of re-hashing the keys is the main bottleneck. But note that Verkle Trees have orders of magnitude more CPU overhead compared to Binary Trees, which are considered hash functions, so it depends on the target tree.
Conversion units
The EIP introduces a concept of conversion units to precisely describe what counts as a moved item for the CONVERSION_STRIDE limit. As currently defined, a conversion unit is:
- Account data: nonce, balance, code hash, and code (if any).
- An account’s storage slot.
Note that one conversion unit implies one or more leaf insertions in the new tree. Both Verkle and Binary propose a unified tree that includes accounts data, storage slots, and accounts chunkified code:
- An account conversion unit implies creating at least two new tree entries:
- BASIC_DATA leaf, containing the version, nonce, balance, and code size.
- CODE_HASH leaf, containing the code hash.
- Depending on the code-chunk size, we’d have to insert N leaves corresponding to each code chunk for the account’s code (if any).
- A storage slot conversion unit implies creating exactly one entry since each storage slot is also a single leaf in the new tree.
The proposed EIP includes in its rationale an important point on why we don’t count each code chunk as an independent conversion unit:
If an account has code, this is chunked and inserted in the VKT in one go. An alternative is including a
CodePhaseand let each inserted chunk consume one unit ofCONVERSION_STRIDE. We decided to not do this to reduce the algorithm complexity. Considering the current maximum code size, the worst case scenario for a block could overflow theCONVERSION_STRIDElimit by 24k/31~=793 units.
At first, this concept might sound over-engineered, but this is because the old tree (MPTs) and the new tree (Verkle/Binary) don’t have the same data in leaf levels. First, the MPTs don’t contain an account code but only the code hash, while the new tree includes code chunks as tree entries. Also, account data such as nonce, balance, and code hash are stored in a single MPT leaf but in more than one in the new tree.
State conversion duration
Considering that the MPTs are read-only, we can determine how many conversion units should be found in the walking. Since we know we copy up to CONVERSION_STRIDE conversion units per block, we can calculate how many blocks the conversion will take.
Note that the migration happens per block and not per slot. The wall clock duration of the conversion process depends on how many missed slots happen in the chain during the conversion process.
Stale data
Note that there are many ways in which a conversion unit we intend to move to the new tree contains stale data and must avoid overriding the value:
- Before EIP-7748 activation, EIP-7612 was activated; thus, the new tree was already getting writes from previous block executions. This means that for a key in the MPT, a more recent value can already exist in the new tree.
- If that didn’t happen before the state conversion started, it can happen during the conversion anyway.
Some examples:
- Conversion unit corresponds to the account’s data: if there was a previous transaction execution that wrote to the account’s balance, this means the MPT balance is stale. Copying the code chunks is still required since transaction execution never triggers code chunkification for existing contracts.
- Conversion unit corresponding to accounts storage slot: a previous transaction could have triggered a write to the storage slot. Thus, the storage slot value in the MPT is stale. Although this value isn’t copied, it still counts since we had to check it.
Pre-EIP-161 accounts
The state conversion is also an opportunity to delete EIP-161 accounts so we can clean them up once and for all instead of passively if they’re touched during block execution.
Preimages
Moving the conversion units from the MPT to the new tree has a catch. Given an entry in the RO MPT, it will live in a different tree key in the new tree since the new tree defines a new way of calculating keys.
This means that the new key has to be computed, so you require the preimage of the MPT key since it’s a hash. This is a big topic that we’ll dive more into next.
Preimage generation and distribution
[Note: this page is heavily based on an existing research post from one of the book authors]
Recommended background
This topic is diving into a subject that can’t be understood correctly in isolation; we recommend previous reading of:
Context
As mentioned in the EIP-7748 Preimages section, we need to calculate new keys when conversion units are moved from the MPTs to the new tree. This calculation requires having the necessary data.
For any of the proposed new trees, we need to calculate the new tree key for:
- An account: we require the account’s address.
- A storage slot: we require the account’s address and storage slot number.
- A code-chunk: we require the contract’s address and its code.
When we do the EIP-7748 walking, clients only have access to the MPT key, which results from hashing addresses or storage slots. Most clients only have these hashed values, so they don’t have enough information to do the listed new tree key calculations. They must have a preimages file to map each MPT key hash to the preimage.
Preimages file
Now we dive into different dimensions of this preimage file:
- Distribution
- Verifiability
- Generation and encoding
- Usage
Distribution
Given that the preimage file is somehow generated, how does this file reach all nodes in the network? The consensus is that it’s probably OK to expect clients to download this file through multiple CDNs. This is compared to relying on alternatives like the Portal network, in-protocol distribution, or including block preimages.
Other discussed options are:
- Having an in-protocol p2p distribution mechanism.
- Distributing the required preimages packed inside each block.
This topic is highly contentious since these options have different tradeoffs regarding complexity, required bandwidth in protocol hotpaths, and compression opportunities. If you’re interested, there’s an older document summarizing many discussions around the topic.
Verifiability
As mentioned above, full nodes will receive this file from somewhere that can be a potentially untrusted party or a hacked supply chain. If the file is corrupt or invalid, the full node will be blocked at some point in the conversion process.
The file is easily verifiable by doing the described tree walk, reading the expected preimage, calculating the keccak hash, and verifying that it matches the client’s expectations. After this file is verified, it can be safely used whenever the conversion starts, with the guarantee that the client can’t be blocked by resolving preimages — having this guarantee is critical for the stability of the network during the conversion period. This verification time must be accounted for in the time delay between EIP-7612 activation and EIP-7748 CONVERSION_START_TIMESTAMP.
Of course, other ways to verify this file are faster but require more assumptions. For example, since anyone generating the file would get the same output, client teams could generate it themselves and hardcode the file’s hash/checksum. When the file is downloaded/imported, the verification can compare the hash of the file with the hardcoded one.
Generation and encoding
Now that we know which information the file must contain and in which order this information will be accessed, we can consider how to encode this data in a file. Ideally, we’d like an encoding that satisfies the following properties:
- Optimize for the expected usage reading pattern: the state conversion is a task running in the background while the main chain runs, so reading the required information should be efficient.
- Optimize for size: as mentioned before, the file has to be distributed somehow. Bandwidth is a precious resource; using less is better.
- Low complexity: this file will only be used once, so a simple encoding format is good. It doesn’t make sense to reinvent the wheel by creating new complex formats unless they offer exceptional benefits while taking longer to spec out and test.
There’s a very simple and obvious candidate encoding that can be described as follows following the example we explored before: [address_A][storage_slot_A][storage_slot_B][address_B][address_C][storage_slot_A].... We directly concatenate the raw preimages next to each other in the expected walking order.
This encoding has the following benefits:
- The encoding format has zero overhead since no prefix bytes are required. Although preimage entries have different sizes (20 bytes for addresses and 32 bytes for storage slots), the EL client can know how many bytes to read next depending on whether they should resolve an address or storage slot in the tree walk.
- The EL client always does a forward-linear read of the file, so there are no random accesses. The upcoming Usage section will expand on this.
If you are interested in knowing how this file can be generated and some analysis about the efficiency of the format, see this research post.
Usage
It is worth mentioning some facts about how EL clients can use this file:
- Since the file is read linearly, persisting a cursor indicating where to continue reading from at the start of the next block is useful.
- Keeping a list of cursor positions for the last X blocks helps handle reorgs. If a reorg occurs, it’s very easy to seek into the file to the corresponding place again.
- Clients can also preload the next X blocks preimages in memory while the client is mostly idle in slots, avoiding extra IO in the block hot path execution.
- If keeping the whole file on disk is too annoying, you can delete old values past the chain finalization point. We doubt this is worth the extra complexity, but it’s an implementation detail up to EL client teams.
Use cases
Stateless Ethereum allows the state of Ethereum to be proven much more efficiently, which has deep implications for the ecosystem.
As explained in this book introduction, the two main motivations are:
- Increasing the gas limit: allowing the Ethereum state to be efficiently proven in SNARKs decouples block verification time from the gas limit.
- Improved decentralization: not requiring disk space to run an EL client allows low-powered devices to join the network and contribute to its security, fulfilling The Verge’s goal of simplifying block validation.
{kind=link}
But the above only scratches the surface of the implications of going stateless. This is an active area of research, and we invite everybody to imagine what is possible and share their ideas.
Next, we dive deeper into which use cases going stateless unlocks. More use cases will be added to this chapter in the following months.
Stateless clients
Overview
A stateless client is a client that can trustlessly verify a blockchain block without storing the whole Ethereum state. Trustlessly is the keyword here — compared with light clients, which rely on an external party to provide the required state to verify the block. Stateless clients can also be named secure light clients.
But what are the blockers for stateless clients to be a reality? As explained in the Trees chapter, the Ethereum state is merkelized; thus, we can create Merkle proofs. However, the problem relies on how big these proofs are, which can become a problem for network distribution and security. All the protocol changes described in this book aim to allow efficient enough proofs to enable stateless clients to participate in the network sustainably and in the worst-case scenarios.
Block verification and required state
Let’s better understand the relationship between the Ethereum state and block verification.
To do this, let’s imagine we’re trying to verify a block that contains a single transaction sending 10 ETH from account A to account B. Omitting some details and just using common sense, we need to check that account A has enough balance for the ETH transfer and gas fees. If this isn’t the case, the transaction must fail.
Note that when a block is received with this transfer, an EL client can’t predict which will be account A, so a priori must have this information for all Ethereum accounts. Not doing so means that a potential transaction would make verifying this block impossible for a stateless client. Stateful clients could still verify, but presumably be the minority. More advanced transactions, such as ones that execute contracts, work the same — clients must have accounts’ contract code and storage state since blocks can contain transactions involving any existing contract.
The main insight is that given a block with transactions, the amount of state that we need to verify the block is orders of magnitude smaller than the complete state. Even further, there’s Ethereum state that hasn’t been used for years but is still required since at any point in time a new transaction touching this state could appear. This tangentially surfaces the need for supporting State Expiry in the protocol, which will be a future chapter in this book.
How would they work?
The following diagram depicts how a stateless client relying on pre-state proofs would work:
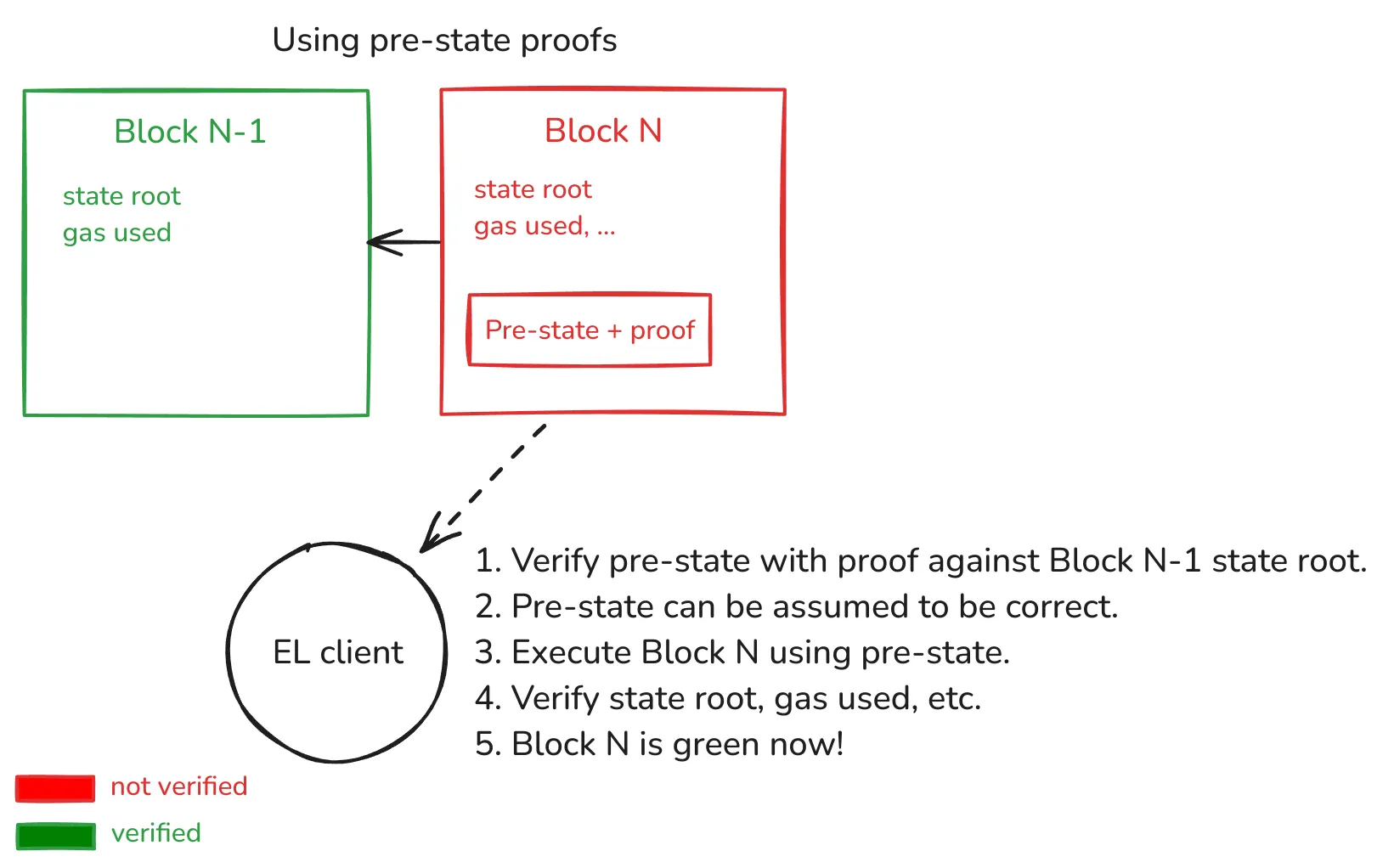
In a fully SNARKified L1 world:
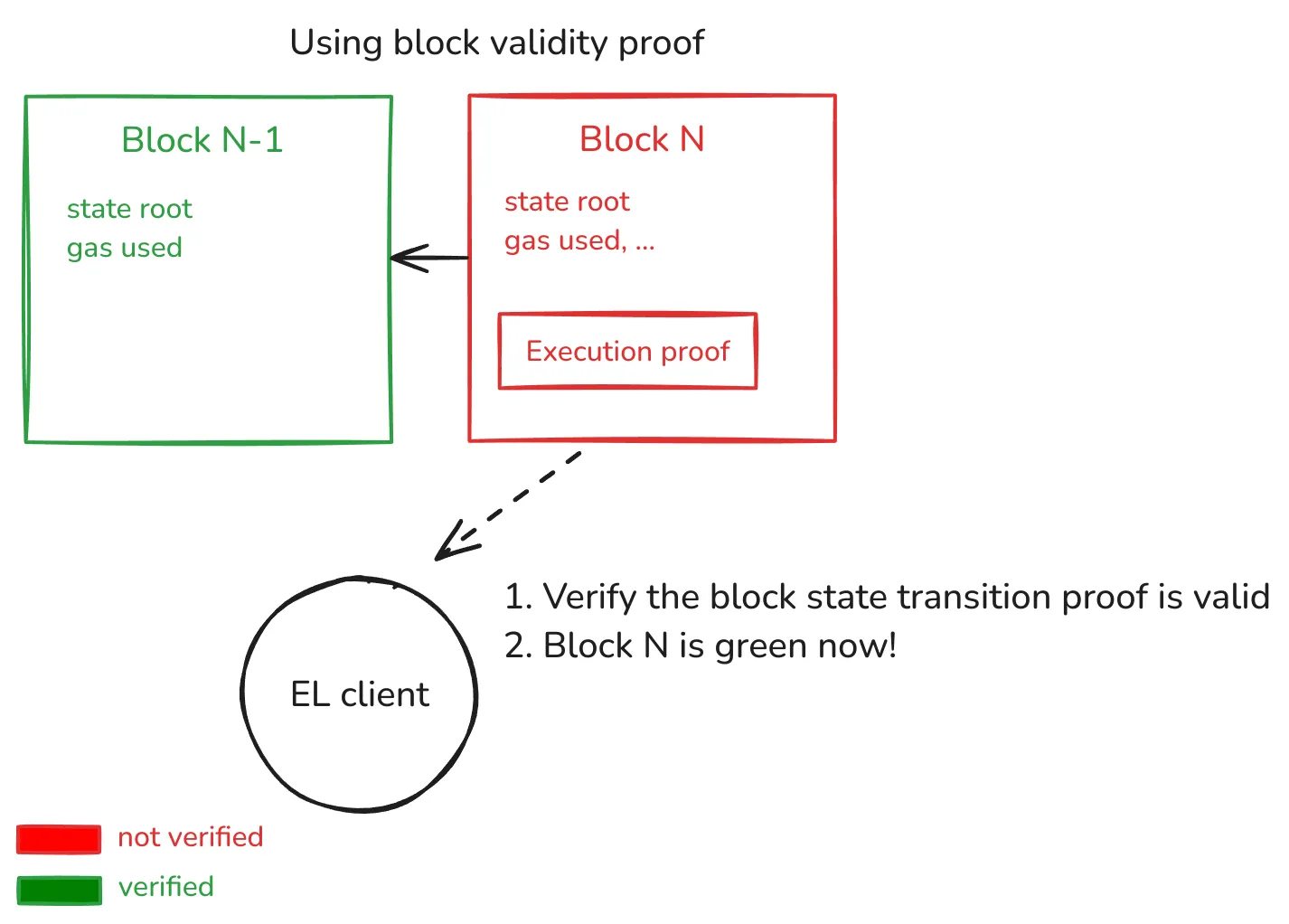
In this setup, the proof is fully proving that the state transition with public inputs:
Block N-1state root (i.e., pre-state).Block Nhash.Block Nstate root (i.e., expected state after executing the tx list on top of pre-state).
This allows us to push further L1 scaling since the EL Client doesn’t have to do any EVM code execution, and the only computational cost is verifying the proof.
There is active research and proposals that might change how execution payloads are validated and executed (e.g., delayed validation). On this page, we stick to how the current protocol works but stay tuned since the book will continue to be updated if these changes are included.
Stateless clients as validators
The above explanations focused on stateless clients verifying the validity of the blockchain without trusting external parties, which is the ethos of Ethereum. However, stateless clients can go further and participate as validators in the network.
Not having the full state means they can’t be block builders since generating the proof indirectly requires having access to the state. This doesn’t mean stateless clients can’t be validators since many validators today delegate the task of block builders to external parties (e.g., using MEV-boost). They could still receive the candidate block with the corresponding proof, verify it is correct, and then propose it to the network.
The implications of stateless validators are an active area of research since they have deep implications for network topology and security. Soon, new chapters will be added to the book to explore this topic further.
Stateless client architecture
One benefit of having stateless clients is that they’re simpler to implement compared with a full node.
Let’s look at the following diagram:
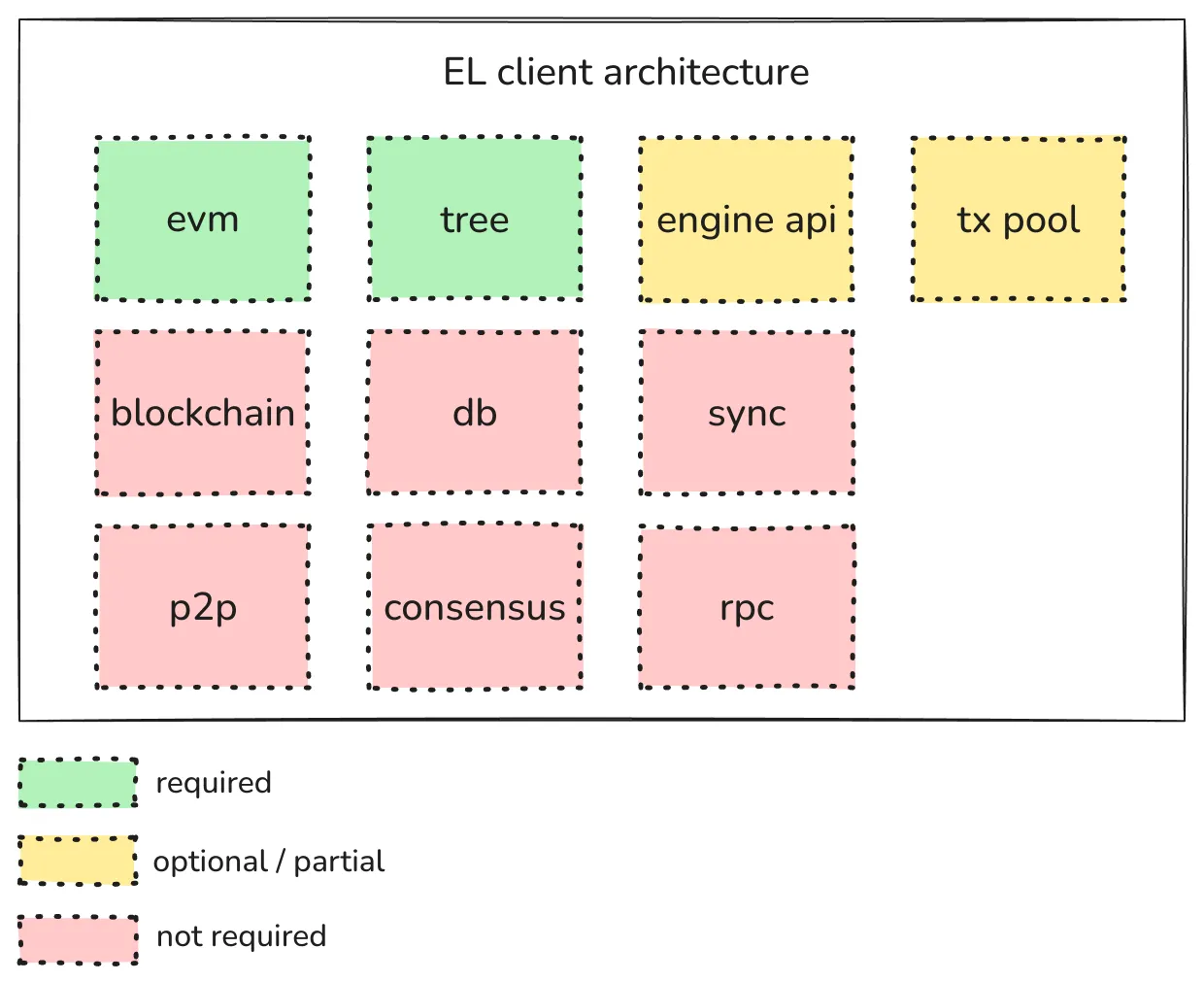
- An EVM implementation is required since block execution is needed.
- A Tree implementation is required since the new state root must be calculated.
- The Engine API and Txn pool should be implemented partially or optionally.
- A full node involves the rest of the components but isn’t strictly required by a stateless client.
Resources
Over the past years, many articles and talks have been made about stateless, mainly on the topic of Verkle Trees. With recent updates to the roadmap, we will continue expanding this section, increasing our coverage of Binary Trees as well.
Introductory material
- Why stateless? - Dankrad Feist’s introduction on his blog
- Possible futures of the Ethereum protocol, part 4: The Verge - Vitalik’s latest update on the stateless roadmap
- Verkle Trees - Vitalik’s intro on Verkle Trees
Video presentations
- Anatomy of a stateless client - Guillaume Ballet, April 2024: an overview of how stateless improves client maintainability
- Recipes for a Stateless Ethereum - Guillaume Ballet, March 2024: a good summary of the use cases of stateless Ethereum
- Verkle Trees 101 - Guillaume Ballet, Ignacio Hagopian, Josh Rudolf, April 2024 - an overview of the EIPs used in Verkle Trees (a lot of it still current for Binary Tress)
- Verkle sync: bring a node up in minutes - Guillaume Ballet, Tanishq Jasoria, September 2023 - a presentation of how stateless clients improve sync algorithms
- The Verge: Converting the Ethereum State to Verkle Trees - Guillaume Ballet, July 2023 - a presentation of the conversion process
- Ava Labs Systems Seminar: Verkle trees for statelessness - Guillaume Ballet, October 2023 - a comprehensive overview of the states of stateless development as of October 2023
- DevCon: How Verkle Trees Make Ethereum Lean and Mean - Guillaume Ballet, Oct 2022
- Verkle Tries for Ethereum State - Dankrad Feist, Sept 2021 - PEEPanEIP presentation
Advanced material
Overviews
- Overview of tree structure - a blog post describing the structure of a Verkle Tree, which is still current with the Binary Tree proposal.
- Overview of cryptography used in Verkle
- Anatomy of a Verkle proof - same as above
- Stateless and Verkle Trees (video) - a dated presentation giving an overview of the stateless effort and Verkle Trees in particular
State expiry
- https://ethresear.ch/t/state-expiry-in-protocol-vs-out-of-protocol/23258
- https://ethresear.ch/t/the-future-of-state-part-1-oopsie-a-new-type-of-snap-sync-based-wallet-lightclient/23395/1
- https://ethresear.ch/t/the-future-of-state-part-2-beyond-the-myth-of-partial-statefulness-the-reality-of-zkevms/23396/1
- https://ethresear.ch/t/compression-based-state-expiry/23443
Analysis
- https://ethresear.ch/t/ethereum-bytecode-and-code-chunk-analysis/22847
- https://ethereum-magicians.org/t/not-all-state-is-equal/25508/3
- https://ethresear.ch/t/data-driven-analysis-on-eip-7907/23850
- https://ethresear.ch/t/a-small-step-towards-data-driven-protocol-decisions-unified-slowblock-metrics-across-clients/23907
State gas costs
- https://ethereum-magicians.org/t/the-case-for-eip-8032-in-glamsterdam-tree-depth-based-storage-gas-pricing/25619
- https://ethereum-magicians.org/t/eip-8058-contract-bytecode-deduplication-discount/25933
Misc
- https://ethresear.ch/t/a-short-note-on-post-quantum-verkle-explorations/22001
Advanced technical write-ups
- Inner Product Argument - Dankrad Feist
- PCS Multiproof - Dankrad Feist
- Deep dive into Circle-STARKs FFT - Ignacio Hagopian
EIPs
Included
Championned
- EIP-4762, gas costs changes for Verkle Trees
- EIP-7709, bypass the EVM to read block hashes in the state
- EIP-7612 and EIP-7748, about the state tree conversion
- EIP-7864, about the proposed scheme for Binary Trees
- EIP-8037, State Creation Gas Cost Increase
- EIP-8038, State-access gas cost update
- EIP-8125, Temporary Contract Storage
Proposed, but not actively championned
- EIP-2584, Trie format transition with overlay trees
- EIP-2926, MPT-based code chunking
- EIP-3102, binary trees
- EIP-6800, structure of a Verkle Tree
- EIP-7736 (verkle) leaf-based state expiry
- EIP-7545, proof verification precompile
- EIP-8032, Size-Based Storage Gas Pricing
- EIP-8058, Contract Bytecode Deduplication Discount
Measurements & Metrics
Development
The future of Ethereum stateless is currently in active development, including research, protocol development, and UX impact.
Stateless community
A diverse set of people and teams are working on all these fronts, including:
- Teams from the Ethereum Foundation led by Stateless Consensus and supported by teams such as the Applied Research Group, Robust Incentives Group, STEEL, Devops, and Cryptography.
- Multiple core developers from EL clients such as Nethermind, Geth, EthereumJS, and Besu.
- Many independent contributors from the Ethereum ecosystem.
Ethereum Fellowship Program (EFP)
Stateless Ethereum has also been part of multiple past EFP projects:
- Cohort three (late-2022):
- Cohort four (mid-2023):
- Cohort five (mid-2024):
Grants
Moreover, the following are ongoing grants actively working on many fronts:
- Stateless expiry (EIP-7736) PoC using Verkle Trees
- Zig EVM implementation to be used in a future stateless Zig client.
If you’re interested in working on any specific stateless topic and need a grant, please send your proposal to stateless@ethereum.org for consideration!
Active Projects
This page provides an overview of the projects currently being worked on by the stateless Ethereum team.
Binary Tree Implementation
Migration of Ethereum’s state tree from the Merkle Patricia Trie to a binary hash tree. The binary tree (arity 2) produces significantly smaller state proofs, compatible with STARK compression. Implementation is underway in Geth and Besu, with a cross-client testnet expected shortly. EF research supports deployment for late 2027 / early 2028. A spec tweak is under discussion regarding the transition activation (one-block delay to avoid circular dependencies).
The conversion mechanism from the existing tree to the binary tree. Uses a system contract to store transition pointers, which simplifies reorgs and snap sync. Preimage distribution (needed to recompute keys in the new tree) is a major prerequisite. The transition strategy follows the EIP-7612 model.
EIP-8037: State Creation Gas Cost Increase
Harmonizes and increases the cost of state creation operations (contract deployment, new storage slots, new accounts) to mitigate state growth under higher block gas limits. Introduces a dynamic cost-per-byte variable that scales with the gas limit, targeting an average state growth of 100 GiB/year. Also introduces multidimensional metering to separate state creation costs from execution gas, allowing larger contract deployments without hitting the single transaction gas limit.
EIP-8038: State-Access Gas Cost Update
Increases the gas cost of state-access operations (SSTORE, SLOAD, CALL, BALANCE, EXT* opcodes) to reflect Ethereum’s larger state and the resulting slowdown. State access costs haven’t been updated since EIP-2929 (Berlin, 2021), while the state has grown significantly. Also fixes the underpriced EXTCODESIZE and EXTCODECOPY operations, which require two database reads but were priced the same as single-read operations.
Compression-based State Expiry
An approach to state expiry through compression: old data is moved out of the active database into flat files, replaced by pointers. Corresponding internal trie nodes are removed to improve I/O.
State Expiry Research
Exploration of several complementary expiry models:
- Leaf-based (EIP-7736 style): individual value expiry, resurrection via Merkle or STARK proof. Resurrection implementation is nearly complete in Geth.
- Epoch-based: each epoch gets a new tree, previous trees remain accessible with a resurrection bitmap.
- “1 year of active state”: exploration of a model where only one year of active state is kept in memory.
BloatNet
A dedicated test network for stress-testing Ethereum’s performance under state growth. Identified a critical threshold at ~650 GB beyond which memory consumption grows exponentially, validator performance degrades significantly, and state access times increase by 40%. Used to produce multi-client benchmarks and validate gas repricing proposals. More information at bloatnet.info.
Cross-Client Execution Metrics
A specification for standardized execution metrics across Ethereum clients. Enables objective performance comparison and bottleneck identification, particularly in the context of L1 scaling and the gas limit increase.
ERC-8147: Locality-Preserving Storage Layout
A compiler-level change (no new opcodes) so that mapping storage keys for the same address land on the same leaf page in the binary trie. Improves spatial locality, cache/DB performance, and reduces witness sizes.
Temporary Contract Storage
Semi-persistent storage managed by a system contract that clears automatically on a fixed cadence (~6 months). Aims to move ephemeral data out of permanent storage to slow long-term state growth.
Partial Statefulness (Selective Snap Sync)
The ability for a node to sync only a segment of the state rather than the full state. Formalized through the OOPSIE concept (Opt-in Ownership of Partial State of Interest, Exclusively).
Mainnet analysis
This section contains multiple analysis done on how stateless protocol changes would behave on mainnet. This helps to understand how different properties such as proof sizes, UX impact, and others would behave on mainnet state access patterns.
Verkle replay
Context
This data is gathered replaying ~200k historical blocks around the Shanghai fork. While they do not give a perfect view of how execution will behave once EIP-4762 is active, it still gives a good indication of what to expect, and how the spec should evolve.
Witnesses
This section explores multiple dimensions of the execution witness design.
Size
Research has been conducted, in order to determine the best structure for a witness. We tried four methods:
- The first one, as specified in the current version of the consensus spec, referred to as type 0. This approach uses the SSZ type
Optional[T], that is yet to be officially included in the spec. - A first variation of the spec, in which prestate values are grouped together in their own list, and poststate values are grouped in their own list as well. This is referred to as type 1.
class SuffixStateDiffs(Container):
suffixes: bytes
# None means not currently present
current_values: List[bytes]
# None means value not updated
new_values: List[bytes]
- A second variation of the spec, in which updates, insertions and reads are grouped in their own separate lists. The suffixes for each of these lists are also grouped as their own byte lists. This is referred to as type 2.
class SuffixStateDiffs(Container):
updated_suffixes: bytes
updated_currents: List[Bytes32]
updated_news: List[Bytes32]
inserted_suffixes: bytes
inserted_news: List[Bytes32]
read_suffixes: bytes
read_currents: List[Bytes32]
missing_suffixes: bytes
- A final variation, where update, reads, inserts and proof-of-absences are grouped, along with their suffixes, into their own lists. This is referred to as type 3.
class UpdateDiff(Container):
suffix: byte
current: Bytes32
new: Bytes32
class ReadDiff(Container):
suffix: byte
current: Bytes32
class InsertDiff(Container):
suffix: byte
new: Bytes32
class MissingDiff(Container):
suffix: byte
class StemStateDiff(Container):
stem: Bytes31
updates: List[UpdateDiff]
reads: List[ReadStateDiff]
insert: List[InsertDiff]
missing: List[MissingStateDiff]
Here are our findings after replaying data:

One can see that the spec is much less efficient than the other types. This is due to the inefficiency of storing Optional[T]. As a result, we didn’t include this method in the rest of the analysis.
When only considering witnesses that were produced after the whole state was converted to verkle, this is what is found:
The maximum and median observed sizes for each type, are summarized in the following table:
| Name | Median (KB) | Max (KB) |
|---|---|---|
| type 1 | 425 | 1285 |
| type 2 | 383 | 928 |
| type3 | 380 | 928 |
While type 2 and type 3 are quite close, one can see that type 3 has better average and maximum sizes.
Witness size breakdown (type 3)
Replaying past blocks, we generated the witnesses and could provide the following size breakdown for type 3 witnesses. This is averaged over ~134k blocks, as the conversion blocks were skipped.
| Component | avg size % | min size % | max size % |
|---|---|---|---|
| keys | 13 | 9 | 49 |
| pre-values | 78 | 7 | 85 |
| post-values | 0.1 | 0 | 47 |
| verkle proof | 12 | 8 | 77 |
Takeaways
The key takeaways are:
- Type 3 witnesses offer a great compression.
- Although post-state values don’t take much size on average, they can take up almost half of it in the worst case. It would make sense to remove them, as validating them requires block execution.
Database
Looking at a fully converted database (conversion + ~134k blocks replayed), we found that the leaf depths could be broken into :
| Depth | Count | Percentage |
|---|---|---|
| 4 | 745822024 | 80.6 |
| 5 | 178484052 | 19.3 |
| 6 | 775718 | 0.1 |
| 7 | 2880 | 0 |
| 8 | 10 | 0 |
Execution performance
This section looks at what part of verkle causes a performance hit and what part improves performance.
Impact of key hashing
In order to estimate the performance impact of Pedersen key hashing, this is a comparison of how long it takes to replay 200k mainnet blocks using Pedersen hashes, vs. sha256:
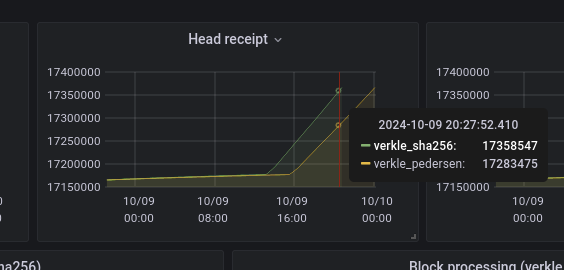
At the end of the sha256 run, so >200k blocks later, the chain was 75072 blocks ahead. This represents a loss of 3 hours per day against sha256. That’s ~12% faster.
Coupled to the fact that Pedersen hashes aren’t quantum resistant, it seems like a good idea to reconsider using Pedersen hashes to compute trees.
On the other hand, adding a new hash function could increase the complexity of future chain SNARKification effort. Choosing Poseidon as a hash function might be an exception, although its overall performance would have to be evaluated once it’s deemed secure.
Tree shape
The following tables are the result of a static analysis of current mainnet data to understand better what the shape of the new proposed trees would look like. This data can be reproduced by using the analysis tool in the eth-stateless repository. All data presented here corresponds to mainnet data at block number 22284325 (~2025-04-16).
Accounts and code-length stats
+-----------+-----------+-----------+
| Accounts |
+-----------+-----------+-----------+
| eoas | contracts | total |
+-----------+-----------+-----------+
| 240876329 | 47994700 | 288871029 |
+-----------+-----------+-----------+
+-------------+---------+--------+-------+-------+
| Code length |
+-------------+---------+--------+-------+-------+
| sum | average | median | p99 | max |
+-------------+---------+--------+-------+-------+
| 32485731750 | 676 | 45 | 11293 | 24576 |
+-------------+---------+--------+-------+-------+
+------------+---------+--------+-----+----------+
| Contract storage slots count |
+------------+---------+--------+-----+----------+
| sum | average | median | p99 | max |
+------------+---------+--------+-----+----------+
| 1287949062 | 26 | 0 | 47 | 68794129 |
+------------+---------+--------+-----+----------+
This data provides a baseline for understanding account and contract code-length distribution.
Stems type counts
As explained in the Data-encoding - Grouping, the new tree has different kinds of stems:
- Account headers stem: encode accounts’ basic data and optimizes top storage slots and code chunks.
- Storage slots stem: grouping of 256 contiguous storage slots for an account.
- Code chunks stem: grouping of 256 contiguous code chunks for an account.
It is helpful to understand the distribution of these kinds of stems in the current mainnet data:
+-----------------------+-----------+--------+
| Stems type counts |
+-----------------------+-----------+--------+
| name | total | % |
+-----------------------+-----------+--------+
| Accounts header stems | 288871029 | 23.40% |
+-----------------------+-----------+--------+
| Storage-slots stems | 943597409 | 76.42% |
+-----------------------+-----------+--------+
| Code-chunks stems | 2223319 | 0.18% |
+-----------------------+-----------+--------+
| Total = 1234691757 |
+-----------------------+-----------+--------+
A total of 1.23 billion stems already provide helpful information to predict the depth of the new potential trees:
- A Verkle Tree would have a depth of ~4 (i.e., log_256(1.23b))
- A Binary Tree would have a depth of ~31 (i.e., log_2(1.23b))
EL clients can employ engineering optimizations to deal with the high depth of Binary Trees, which can be explored more in-depth in this external article. In any case, knowing this depth helps predict special cases of protocol proofs.
For example, for FOCIL or stateless mempools, assuming the depths predicted above, proving a single account nonce/balance in both cases then means:
- Verkle Tree: 4*32+[C1/C2]=160 bytes from required commitments plus the IPA/Multiproof (28+1)*32+32=576 bytes. So, a total proof size of ~736 bytes.
- Binary Tree:
- For contracts: (31+8)*32=1.22KiB.
- For EOAs: (31+1)*32~=1024 bytes for EOAs.
- The difference is because the eight levels in the group can be compressed better in the EOA case since there are known empty hashes in siblings.
The example above is only relevant for the described cases (i.e., stateless mempool or FOCIL). For mainnet blocks, each proof type will shine differently in different dimensions (i.e., proof size, time to compute, verification time, etc). In particular, for mainnet blocks, a Binary Tree proof would be SNARKified compared to the Merkle Tree proof, which makes sense in the mentioned cases. Also note that in some inclusion list scenarios, it can make sense to leverage aggregating more than one account opening in the same proof.
Stems filling stats
An interesting question is to understand how “filled” these 256-groups are. Although EL clients can efficiently serialize these groups with different strategies, it is still worth understanding this dimension to build the right mental model of how a mainnet tree would look.
+-----------------------+---------+--------+-----+-----+
| Stems non-zero values count distribution |
+-----------------------+---------+--------+-----+-----+
| name | average | median | p99 | max |
+-----------------------+---------+--------+-----+-----+
| Accounts header stems | 4 | 2 | 74 | 194 |
+-----------------------+---------+--------+-----+-----+
| Storage slots stems | 1 | 1 | 5 | 256 |
+-----------------------+---------+--------+-----+-----+
+------------------------------------------------+
| Storage-slot stems with single non-zero values |
+------------------------------------------------+
| 871033634 |
+------------------------------------------------+
The first table shows stats on how filled stem groups are for different kinds of stems. For example, account header stems always have two non-zero value items (BASIC_DATA and CODE_HASH), but optionally, they can have more items in the case of contracts (64 storage slots and 128 code-chunks).
The Storage-slot stems with single non-zero values table zooms in on how many storage-slot stems only have one non-zero value:
- ~92% of storage-slot stems (868m/939m), and ~71% of all stems (868m/1.23b)
- These items reflect Solidity hashmap usages since those entries are spread in all the storage slot address space, generating stems with only one non-zero value.
- The ratio of 71% suggests that EL implementations must heavily optimize the efficient serialization of these stems.
- For leaf-level state expiry, expired data in these stems wouldn’t reclaim much space since we’re only deleting 32 bytes (single non-zero value) but keep the corresponding stems, which aren’t collapsed — this is more significant in a Binary Tree scenario than a Verkle Tree one because of the arity. However, this needs to be investigated in detail since it depends on how many of these stems expire in an average expiry epoch.
Final words
The provided static analysis helps understand the shape of the new tree in the mainnet. But there’s another dimension, which is how the grouping allows more efficient state access, but that will be explored soon by doing a dynamic analysis of mainnet state access patterns.
SIC calls
The Stateless Consensus team hosts the Stateless Implementers Calls, which run bi-weekly.
Schedule and agenda
Scheduled calls and their corresponding agendas are in the github ethereum/pm repository. In these calls, we share and discuss any progress made on stateless Ethereum efforts.
The calls are open, so anyone is welcome to join!
Previous calls
You can see summaries and call recordings in the history page.
SIC calls history
- Call #51: May 04, 2026
- Call #49: March 09, 2026
- Call #48: February 09, 2026
- Call #47: January 27, 2026
- Call #46: January 12, 2026
- Call #45: December 1, 2025
- Call #44: October 20, 2025
- Call #43: October 06, 2025
- Call #42: September 22, 2025
- Call #41: Aug 25, 2025
- Call #40: Aug 11, 2025
- Call #39: July 28, 2025
- Call #38: July 14, 2025
- Call #37: June 02, 2025
- Call #36: May 19, 2025
- Call #35: May 5, 2025
- Call #34: April 21, 2025
- Call #33: April 7, 2025
- Call #32: March 24, 2025
- Call #31: February 24, 2025
- Call #30: February 10, 2025
- Call #28: December 2, 2024
- Call #27: November 4, 2024
- Call #26: October 21, 2024
- Call #25: September 23, 2024
- Call #24: September 9, 2024
- Call #23: August 26, 2024
- Call #22: July 29, 2024
- Call #21: July 15, 2024
Call #51: May 04, 2026
Team updates
- Binary Tree implementation: @gballet added an extra field in the Binary Tree to explicitly tag whether a leaf is an account, storage slot, or code.
- This removes ambiguity encountered in
evm t8n’s state dumps, by making them match that of the old MPT layout. This reduces maintenance overhead on the execution specs side, since calling code can treat the Binary Tree much just like the previous trie. - This also allows reuse of prior execution-spec-tests from 2024, helping accelerate testing and reducing divergence across implementations.
- @kt2am1990 (Besu) coordinated with @CPerezz19 to align empty-block state roots between Besu and Geth for cleaner benchmarking.
- Karim is refactoring the Besu binary-tree branch into a cleaner version designed for easier merging with main branches, while preparing support for parallel execution and BAL optimizations.
- @CPerezz19 offered to add Besu binary-tree support into state actor tooling so Geth and Besu can generate identical databases for cross-client performance comparisons.
- The team agreed that BALs (block-level access lists) should integrate cleanly with Binary Trees since they track modified leaves and do not depend on MPT-specific structure.
Interop recap
- @gballet summarized recent discussions with @vbuterin and others around Validator-Only Partial Statefulness (VOPS).
- There is broad agreement to avoid naive Unified Binary Trees (UBT), since validators still need enough intermediate state to validate balances, nonces, and transaction correctness.
- The preferred direction is partial statefulness with domain separation:
- accounts
- code
- nullifiers
- storage
- The current proposal uses a 2-bit tagging scheme, while Vitalik suggested expanding to 16 bits for future extensibility.
- Recent Geth merges also support grouping internal nodes at depth 5–6, improving read/write performance by serializing grouped nodes.
- To support EIP-8141 - Frame Transactions, the first 64 storage slots may be duplicated inside the account stem to improve access while preserving lightweight validator sync.
- Snap sync could then focus mainly on account + code trees (optionally nullifiers) without requiring full storage sync for validators.
- A hybrid fallback design was also discussed: keeping one branch as MPT and another as Binary Tree.
- @gabrocheleau noted this could also help future state expiry models where multiple trees coexist with rolling expiration.
32 byte addresses (@gballet)
- @gballet reviewed how Ethereum currently handles addresses inside the Binary Tree key hashing flow.
- Ethereum addresses are 20 bytes, derived from hashed public keys and truncated, then stored with 12 leading zero bytes to align them to 32 bytes.
- The spec was recently updated to use big-endian ordering to avoid unnecessary byte-swapping inside the EVM and simplify processing.
- One alternative considered was hashing the 20-byte address followed by 12 zeros and the slot separately, but the group preferred keeping the current approach for compatibility and implementation simplicity.
- Gottfried Herold pointed out that prepending 12 zero bytes nearly doubles hashing cost by crossing the 512-bit internal hash block boundary.
- He argued the padding gives no cryptographic benefit since hash functions already encode input length, making the zeros mostly unnecessary overhead.
- Guillaume noted the padding was originally chosen partly to help ZK-VM implementers expecting 32-byte alignment.
- The team will gather more feedback from ZK-VM teams and evaluate implications for Poseidon hashing before deciding whether changes are worthwhile.
Update on 8188 prototype (@ngweihan_eth)
- @ngweihan_eth presented progress on the EIP-8188 prototype for state tiering using metadata that tracks last write times.
- The prototype adds 4 bytes of metadata to accounts and storage slots, tracking writes only (not reads) to avoid gas overhead and UX complexity.
- This lets clients distinguish active vs inactive state and move older trie nodes out of PebbleDB into flat-file storage.
- In testing:
- over 80% of trie nodes were moved to inactive flat files
- active trie size dropped to ~32 GB, small enough to fit in memory
- metadata overhead was only a few hundred MB
- The goal is to improve performance immediately by shrinking the hot database, even before full state expiry mechanisms exist.
- Han plans to present benchmarking results at the next ACD in two weeks.
- A major discussion focused on whether reads should also refresh metadata:
- Milos Stankovic raised concerns that some state is read often but rarely written, which could incorrectly mark it as inactive
- Han and Guillaume argued that updating metadata on reads would introduce too many extra writes and gas costs
- One compromise discussed:
- the first read in an epoch could trigger a metadata write, balancing correctness with cost
- @kt2am1990 suggested a dedicated opcode to explicitly refresh metadata on reads, while Gottfried suggested cheaper unchanged-value writes might achieve the same effect without new opcodes.
- The team agreed to continue exploring these tradeoffs with both client teams and EVM developers before finalizing the model.
Call #49: March 09, 2026
Team updates
- Binary Tree implementation: @gballet fixed a major performance issue by stopping unnecessary full-tree recomputation and limiting work to the parts that actually changed.
- The Binary Tree structure still needs some cleanup for clarity and maintainability, and discussions are ongoing on how best to revise it.
- @kt2am1990 (Besu) is keeping the binary-tree implementation aligned with the fast-moving main branch and plans to spend time this week updating it.
- The teams see these fixes as important groundwork for future Binary Tree work and overall stability.
Issue with binary-tree key computation function
- @gballet identified a spec issue in the Binary Tree key computation flow around endian representation.
- The problem is that the
treeIndexstarts from a naturally big-endian storage offset, is then serialized as little-endian before hashing, and is effectively interpreted back in the original order afterward. - This is less a performance issue than a readability and correctness issue: the extra conversion makes the logic harder to follow and easier to implement incorrectly across clients.
- @gballet suggested simplifying the spec so the
treeIndexstays in big-endian form throughout this step, removing the unnecessary flip. - One source of confusion is that the storage offset can overflow into a 33-byte value before being split into:
- a 32-byte
treeIndex - a 1-byte suffix
- a 32-byte
- Guillaume noted this ambiguity already caused a real bug in Geth, which was fixed recently, and may be worth double-checking in other clients as well.
- He plans to open a PR to update the spec.
- More broadly, the discussion reinforced the need to make the Binary Tree structure easier to read and less error-prone across implementations.
Tiered State Write Pricing
- @ngweihan_eth presented a proposal to price writes based on how long a state has gone untouched, while leaving reads unchanged for predictability and compatibility.
- Proposed tiers:
- Active: state untouched for less than 1 year
- Idle: state untouched for 1–2 years
- Dormant: state untouched for more than 2 years
- The goal is to make writes to older state more expensive, discouraging long-term inactive state bloat and supporting storage tiering across faster and slower hardware.
- In practice:
- active state could stay in fast storage
- idle state could move to slower but still efficient storage
- dormant state could move to cheaper, slower storage
- A key implementation question was how “activity” should be refreshed:
- @gballet noted that automatically updating freshness on reads is too complex
- the simpler approach is to require an explicit transaction to refresh state activity
- This creates a UX trade-off: users may need to manually refresh important state to avoid it becoming more expensive to update later.
- The discussion also surfaced practical access concerns:
- dormant state cannot become so slow to access that it breaks normal usage
- more asynchronous access models may only make sense for deeper archival data, not ordinary dormant state
- @misilva73 asked whether it would be better to introduce separate storage structures for active and dormant state instead of modifying the current tree.
- The response from @ngweihan_eth and @gballet was that new storage forms may help in theory, but broad migration is difficult and existing contracts make disruptive redesigns hard to adopt
- the group leaned toward evolving the current model rather than introducing a parallel structure
- Compatibility remained a central concern:
- existing contracts are hard to migrate
- the current Merkle Patricia Trie is still a core bottleneck
- simply layering new storage forms on top would not fully solve the underlying scalability problem
- The group also discussed incentive and game-theory concerns:
- @gabrocheleau and @ngweihan_eth noted that users may send transactions just before inactivity thresholds to keep state active
- multiple users writing to the same dormant state could create fairness issues where one user pays the reactivation cost and others benefit afterward
- The view was that these trade-offs may be acceptable if inactivity windows are long enough and pricing is tuned carefully.
- Next:
- @ngweihan_eth invited feedback on the proposal
- the team will keep refining the pricing model while watching implementation complexity, UX impact, and incentives
Call #48 February 09, 2026
Team updates
- @gballet (@go_ethereum): merging transition code into Geth; identified a potential spec tweak affecting binary-tree handling that should be aligned before starting the testnet.
- @kt2am1990 (Besu): updating the binary-tree branch to be current; aiming to have a Besu + Geth testnet running within ~1–2 weeks.
- @CPerezz19:
- Enhanced the state actor library to support binary-tree bloating to measure worst-case performance and gas-limit behavior.
- Implemented partial-stateful nodes enabling snap sync of selected state segments; demo: syncing large targets (e.g., USDC-related accounts) from a 50+ GB database in ~30 minutes.
- Rebased on top of BAL Devnet 2 to test block processing and state root proofs under the binary-tree model (protocol correctness + performance validation).
Spec tweaks regarding transition using system contract for storing pointers (@gballet)
- Background: tracking transition state via a system contract can create a circular dependency at the fork point, complicating bootstrapping (opening/reading the state tree) and risking error masking if both trees must be opened simultaneously.
- Proposed tweak: adopt a one-block delay in transition activation:
- Fork block remains fully on the legacy MPT.
- Binary-tree writes begin on the following block.
- Rationale:
- Avoids needing to open both trees at once.
- Aligns with the existing operational pattern of delaying conversion after activation.
- Client feedback:
- @kt2am1990 preferred this over timestamp-based workarounds and committed to trying it in Besu.
- Next: continue discussion; update the spec if this proves the best solution.
Presentation of ERC-8147 — Locality-Preserving Storage Layout for Binary Trie (@ngweihan_eth)
- Concept presented by @ngweihan_eth: improve storage locality in the binary trie by adjusting compiler key derivation for mappings so related keys for the same address land on the same leaf page.
- Properties:
- No new opcodes required; primarily a compiler change (lower developer burden).
- Improves spatial locality and expected DB/cache behavior.
- Constraints:
- Supports up to 256 mapping “chunks”, with fallback behavior if exceeded; considered sufficient for current patterns but should be monitored.
- Discussion:
- @gabrocheleau raised concerns about proxy patterns using explicit storage slots that could fall outside the assumed range; acknowledged as follow-up.
- @gballet confirmed the approach should generalize to mappings and arrays.
Binary Trees re-designs & performance considerations from teams (@CPerezz19)
- Core question: unified binary tree vs domain-separated subtrees (accounts vs contract storage).
- Domain separation arguments (raised by @CPerezz19 and others):
- Helps partial statefulness and archival/state-expiry tooling by distinguishing account vs contract storage in the DB.
- May improve caching strategies (e.g., keeping account trees hot in RAM) and speed up state-root computation.
- Can be implemented via key prefixes or separate trees; worst-case depth impact is small (≈ +1).
- Counterpoints / prior feedback:
- Outcome:
- No final decision; benchmark both models (witness sizes, root computation time, overall performance).
- @CPerezz19 to publish research/performance data to guide future design choices.
Stateless summit
- @gballet announced a Stateless Summit scheduled for April 1 and encouraged participants to register.
- Goal: align teams on specs, implementations, and open design decisions; share progress and coordinate next steps.
Call #47: January 27, 2026
Team updates
- @gballet (@go_ethereum) reported progress on state expiry, with the resurrection implementation nearly complete and undergoing debugging. Code from Han for expiry is expected to merge this week. Guillaume also noted a potential roadblock with the test framework requiring a large codebase refactor, suggesting the alternative of producing and sharing blocks in dev mode to cover interrupts while giving the testing team more time to strategize.
- Thomas Zamojski (@HyperledgerBesu) updated that the Besu team is focused on preimage acquisition and verifying the binary tree root hash by resurrecting Besu’s dev mode to generate blocks locally and validate against Geth. The team is not yet ready for binary tree optimizations and is awaiting benchmarking information.
Roadmap updates and binary trees schedule
- @gballet provided a brief roadmap update following a meeting with the Ethereum Foundation research team in Berlin. The main takeaway is that the research team supports scheduling binary trees for late 2027 or early 2028, potentially for the J* fork, and showed a good understanding of the reasoning for picking EIP-7612 style transition. These timelines are not yet official ACD decisions.
- Benchmarking is necessary to confirm the binary tree’s presence on the roadmap, especially to assess performance impact and I/O due to data written.
- The team plans to use Geth’s dev mode to produce and export blocks for sharing between clients for debugging and testing inter-client operability, potentially leading to a testnet.
Transition strategy and ecosystem engagement
- The research team agreed with the proposed transition approach. A shadow fork is desired once preimage distribution issues are resolved. The plan involves a dev mode conversion first to ensure agreement between Besu and Geth, followed by a shadow fork similar to previous vertical testnets.
- @gballet announced a crucial effort to engage the wider ecosystem—including L2s, DApps, and wallets—to gather feedback on the statelessness rollout and the tradeoffs involved. The plan is to conduct interviews and distribute a questionnaire to major players.
State expiry models
- Two models were discussed: leaf-based expiry (e.g., EIP-7736 style) and epoch-based expiry.
- Leaf-based model: the main challenge is resurrection UX, which involves passing a proof (Merkle or STARK-based) to revive expired data. Wallets might be expected to hold the data and handle proof provision, allowing higher transaction fees to cover resurrection cost and minimizing UX impact for non-censored users.
- Epoch-based model: subsequent epochs have new trees and previous trees remain accessible with an updated resurrection bitmap. This avoids address space extension but requires keeping a hash of the bitmap for every epoch, causing block size to grow.
- @URozmej expressed concern about relying on third parties to store state, preferring a backup plan where old trees could be frozen and distributed via BitTorrent. @gballet countered that BitTorrent is unreliable and suggested a more robust, incentivized mechanism like rainbow staking.
- @CPerezz19 raised the idea of viewing state expiry primarily as a mechanism for data reduction rather than focusing on a flawless revival mechanism, suggesting a change in user mindset where cold state data becomes the user’s responsibility.
Address-based storage proposal
- @ngweihan_eth presented an early-stage idea inspired by Vitalik’s User-Associated Storage concept: address-based storage. Based on binary trees, the proposal introduces a second tier of storage where per-user contract state (like token balances) moves into the user’s account, namespaced by the contract address, to improve data locality.
- Advantages: better I/O efficiency, lower gas costs, compatibility with proxy patterns, compiler friendliness, and improved compatibility with state expiry and partial stateless nodes.
- Downsides: increased witness overhead for ZK-EVMs, added complexity for client developers, and applicability only to new contracts.
- Migration of existing storage is not feasible due to the requirement of preimages for all storage. Individual contracts would need to perform manual migrations, possibly pausing their protocol.
- @URozmej asked whether the storage was bounded; @ngweihan_eth clarified it reverted to an unbounded design. @gballet questioned whether a subtree was necessary, suggesting the new storage could reside at the same level as regular storage. @CPerezz19 argued the subtree preserves structure and facilitates easier reasoning about account storage.
Call #46: January 12, 2026
New EIP proposal by Vitalik (User-Associated Storage, “UAS”)
- Overview: associate contract storage with users to cut gas and enable user-scoped expiry. Storage for a (contract, user) pair can live in the user’s account header instead of the contract’s storage.
- Presentation: @vbuterin walked through the UAS EIP. Estimated savings up to ~2,000 gas per tx on common paths.
- Access model:
- Users can “promote” up to 16 privileged slots into their account header for faster access and simpler expiry.
- Contracts opt in via new opcodes (
USSTORE/USLLOAD). No ERC-20 standard change required, but token contracts must adopt the new opcodes. - Anti-spam: users must explicitly set privileged user storage; contracts cannot set their own storage as self-privileged in user accounts.
- Limits & layout:
- Per user: 16 privileged slots.
- Per contract: up to 256 user mappings.
- Backed by a binary-tree layout; discussion on shrinking page size from 8K → 4K/2K for DB performance.
- Transition & compatibility:
- Works best with the binary tree; theoretically possible on MPT but header management is complex.
- Rationale:
- Even without near-term state expiry, gas savings justify adoption.
- Groups user-related state to expire together later, curbing long-term bloat.
Team update
- Benchmarks & code size limits:
- @CPerezz19 finalizing EIP-7907 benchmarks (code size limits / gas adjustments), targeting ETH Research + potential EthCC presentation. Resolved cache issues by resetting mainnet DB and using Geth dev mode.
- Formal partial-statefulness specs being integrated into execution tests to stress worst-case storage writes (e.g., EOA→non-empty transfers).
- @gballet + @CPerezz19 +@vbuterin: raising contract code size needs protocol-level changes. Contracts ≳80 KB run into current tx gas ceilings. Options discussed:
- Keep size limit; increase certain gas costs.
- Temporarily raise tx gas limit (e.g., 20M).
- Multidimensional gas pricing (unlikely on current roadmap).
- Goal: balance higher state-creation costs with a code-size increase to avoid blocking deployments while controlling bloat.
- Mario Vega (EELS) + @CPerezz19: prefer precomputed gas usage for deterministic tests; waiting on a PR that automates gas calc across tests before merging changes.
- Org & roadmap:
- Damien from Nethermind stepping up in light of @jasoriatanishq leaving Nethermind.
- @gballet coordinating binary-tree adoption and roadmapping (including EIP-797 and code-size track).
- @ngweihan_eth (@StatelessEth) demoed the Event Ops lab page for state growth/expiry views here; expects backend fixes by week’s end; feedback requested.
Proposal to use system contract for transition
- Idea: store state-transition pointers in a system smart contract (consensus state) instead of off-chain DBs.
- Effects:
- Pointers must be set before block-root calc.
- Simplifies reorgs as pointers naturally roll back with state.
- Snap sync benefits: pointers are fetched via standard state sync.
- Reads bypass EVM execution for these pointers to avoid overhead.
- Status: partial prototype tied to EIP-8032; @gballet will continue after feedback from Nethermind and Besu.
Draft EIP: Temporary Contract Storage
- Concept presented by @ngweihan_eth: semi-persistent storage managed by a system contract that clears on a fixed cadence (e.g., ~6 months).
- Interface: new TMP Store / TMP Load opcodes with gas similar to regular SSTORE/SLOAD.
- Purpose: shift ephemeral data out of permanent storage, easing pruning and slowing long-term growth (does not shrink today’s state).
- Client concerns: separate handling for reorgs and RPC, plus integration with the unified binary tree.
- Open questions:
- Interval parameterization and gas modeling.
- App-level fit: balances likely poor candidates; event/ops data better.
- Implementation shape: two alternating trees to guarantee lifetime; a ~7-day cadence was noted as a natural baseline (aligns with optimistic rollup assumptions).
- Next: validate app patterns and finalize clearing intervals/gas before advancing.
Call #45: December 1, 2025
Team updates
- @CPerezz19 (@StatelessEth) is extending L1 scaling experiments by adding more scenarios to EEST and spamoor to bloat ERC20s for state/contract-size testing, and is building a state analyzer tool for the lab page. State tests are already running successfully on Nethermind, and benchmarks are being refactored to respect the 60M gas cap introduced in Fusaka.
- @gballet (@go_ethereum) continues Binary Tree implementation work in Geth; an executable version exists, and he plans to resume coordination with Mario Vega on using the updated execution spec.
- Mario Vega (EELS) checked in with @CPerezz19 on
EEST(no blockers, recent state tests passed on Nethermind), flagged the ongoing revamp of theexecutecommand, and offered to coordinate on refactoring tests and benchmarks to comply with the 60M gas cap; Carlos is already updating benchmarks and awaiting review on thespamoorchanges agreed with PK from EthPandaOps.
CodeChunks inclusion in the binary-tree leaf
- The current design stores the first 128 bytes of contract code directly in the Binary Tree leaf alongside basic account data, improving locality and immediate access. A proposal would move code chunks entirely out of the leaf into a separate structure to enable code deduplication and use the freed header space to increase inline storage slots from 64 to 192.
- @gballet highlighted downsides: most contracts have small code that fits in the header today, so externalizing code would usually add an extra node per account, growing the tree and increasing structural complexity.
- Earlier constraints from Portal Network (which motivated merging code and account data for minimal download sets) are no longer active. The group agreed to treat the layout as re-open for discussion, but any change will depend on measurements comparing final tree size and overhead between the current and proposed designs; these measurements are planned before the next call.
Communication channels with app-layer and other teams
- @gabrocheleau proposed creating a single, general Telegram group for external teams (app-layer, infra, tooling, etc.) instead of multiple fragmented channels, to centralize feedback on how teams use state and what trade-offs they can tolerate around state expiry and state economics.
- @gballet agreed a single channel would be easier to maintain. The plan is for Gabriel to first line up ~5–10 interested teams, then create the group and invite both stateless-core participants and external teams so the channel starts with a clear mandate and critical mass.
Call #44: October 20, 2025
Team updates
- @gballet (@go_ethereum) and @kt2am1990 (@HyperledgerBesu) reported partial test success; some vectors fail due to a suspected RLP encoding discrepancy between Geth and Besu.
- @kt2am1990 (@HyperledgerBesu) is investigating problematic data dumps from Guillaume and will collaborate with Thomas Zamojski to accelerate resolution. Goal is to resolve Geth–Besu interoperability for binary-tree implementations.
- Also reported that @jasoriatanishq (@NethermindEth) had deprioritized binary-tree work pending these test results..
- Mario Vega is leading the rebase of the weld, targeting completion within ~two weeks. This rebase is critical to integrate binary-tree support into the updated repo structure. Carlos will assist with plugging binary trees post-rebase, with support from Mario’s team. Completion enables broader stateless test vectors and validation.
- @gabrocheleau shared that (EthereumJS)’s verkle support is deprecated and has been removed from the repo. Binary-tree support is maintained for testing. Gabriel is also drafting a state-expiry survey for wallet/app/provider teams on state management, requirements, costs and potential incentives. Draft to be shared soon.
- @ngweihan_eth shared that he is researching and discussing in-protocol vs out-of-protocol state expiry: https://ethresear.ch/t/state-expiry-in-protocol-vs-out-of-protocol/23258. Also exploring contract-level state expiry (expiring storage of unused contracts). Estimated reduction: 50–60 GB (~20% of total storage). Approach favors client-side reclamation without immediate protocol changes; Wei Han plans to formalize an EIP and seek discussion.
Compression-based state expiry
- Guillaume presented his initial findings and research on state compression: explorations target ~20% state size reduction initially, with pathways up to ~80% via more granular expiry to improve DB performance and storage efficiency.
- Compression-based expiry: move old account/slot data out of DB into flat files. Replace expired values with pointers; drop internal trie nodes to improve I/O and reduce bloat. Writes to archived data reinsert into main state; thresholds proposed to balance recomputation cost. Serves as a gradual path toward potential in-protocol expiry.
- Performance notes: even a 20% whole-account expiry yields notable DB speedups in client benchmarks; leaf-level expiry targets larger savings (80%) but requires more work.
- Economic/fee alignment: if expiry becomes in-protocol, higher gas for writing to expired/archived storage (e.g., discussed alongside upcoming EIPs like 8037/8038) could incentivize efficient state usage. Even when out of protocol, builders may deprioritize transactions resurrecting expired state unless tipped appropriately.
Call #43: October 06, 2025
Team updates
- @gballet (@go_ethereum) is assisting @CPerezz19 in reactivating execution spec tests to be binary-tree compatible and proposed a new gas-accounting PR (EIP-8032) aimed at stemming state growth.
- @CPerezz19 is working with @gballet on binary-tree test fixes, has identified and fixed bugs in the binary-tree implementation, and continues BloatNet work while pushing benchmarks to EELS for integration with Kamil’s tool from @NethermindEth.
- Thomas Zamojski (@HyperledgerBesu) shared that @kt2am1990 is working on the transition and awaiting binary-tree test returns. Thomas has been focused on gas optimization and will return to statelessness, picking up the transition topic from Karim.
- Gabriel Rocheleau (EthereumJS) shared that EthereumJS could consider supporting stateless clients for future testnet usages, but absence of execution witnesses & proofs on binary tree testnets makes this impossible for the time being.
Updates on binary trie t8n self-fixtures consumption progress. (@CPerezz19)
- State diffs are the primary blocker; more than half of the 500+ tests pass when excluding state diffs.
- Temporary removal of state-diff tests to simplify rebases and speed PR merges.
- Fixture refactor to align vertical and binary trees; transition to EELS with a Python reimplementation to generate fixtures natively.
- Test representation moving from separate allocs to a unified key–value list; adopt SHA256 for simpler key computation.
Discussion on code chunks inclusion in the tree (@CPerezz19)
- Proposal to store code chunks separately and deduplicate across accounts, removing the preferential treatments of the first 128 chunks in the account leaf.
- Treat code and storage uniformly to simplify the binary-tree structure; decision postponed pending further research.
BloatNet updates (@CPerezz19)
- Unblocked on merging PRs to EELS; submitted fixes on stop-contract handling and benchmarking.
- Multi-opcode tests in place; key single-opcode tests focus on L1 scaling (SSTORE on the largest ERC-20s; SLOAD into empty/likely-empty slots).
- Goal is to integrate with Kamil’s benchmarking tool from @NethermindEth; cross-team call scheduled. Stop contracts not specifiable across tests remains a major issue.
- Syncing tests: collaboration with partners; clients like Reth and Erigon are actively debugging syncing issues. Several benchmark runs executed; target is five clients in one pass to avoid heavy snapshot re-runs.
Findings on post-EIP6780 selfdestructs (@ngweihan_eth)
- Around 2.7M unique self-destructed accounts (~1% of accounts; ~0.03% of storage slots); activity peaked shortly after Dencun and has since declined.
- Small current footprint noted by @ngweihan_eth; @gballet flagged cumulative risks if zero-slot accounts persist.
- Next steps: gather more precise frequency data to assess long-term effects and inform potential pruning/removal proposals.
Call #42: September 22, 2025
Devnet Progress & Performance:
Karim Taam released a new Docker image for the upcoming devnet and has improved transition implementation by pre-downloading preimages to a database, rather than a single RPC call per preimage resolution. Testing is currently underway.
Blobnet & Benchmarking Updates
Carlos Perez shared progress on Bloatnet syncing, including fixes for peering issues, and announced the readiness of the multi-opcode benchmarking PR, which will streamline future benchmarking efforts.
Ethereum State Analysis Insights
Wei Han Ng presented a detailed analysis of Ethereum mainnet state access patterns. Key findings include that EOAs have longer activity spans than contracts, with 55% of contracts active for only one block and 80% of accounts active for less than a year. The analysis also showed a high concentration of contract deployments, with the top 100 bytecodes and factories accounting for significant percentages of all contracts, indicating widespread bytecode reuse.
Based on the data, Wei Han Ng proposed several ideas:
- Re-evaluating state expiry periods, suggesting that keeping data for over a year might be sufficient.
- Implementing a temporary storage model where slots automatically clear after a set period.
- Making contract deployment cheaper for reused bytecodes through mechanisms like a same-block duplicate discount or a global code registry.
- Introducing progressive per-address storage pricing to disincentivize excessive slot spamming, though acknowledging potential drawbacks for successful contracts.
Guillaume Ballet discussed the implications of removing storage slot deletions (where writing to zero no longer deletes a slot) on state bloat, noting that current data suggests a significant impact that would necessitate repricing.
Devnet Transition & Pre-image Distribution
- A new key computation format for the next testnet using SHA-256 hash was also discussed to simplify client implementation by eliminating the need for pre-image distribution. This was rejected, as is makes things more complex after all.
- The next devnet will not include a transition to facilitate Geth’s participation due to slow merging. Future devnets with transitions will require a clear specification for pre-image downloading.
State Analyzer
Plans were announced for a state analyzer panel on the EthPandaOps Lab website, providing a state dashboard with various metrics that will be regularly updated to track patterns.
Call #41: August 25, 2025
1. Team updates
-
@kt2am1990 (@HyperledgerBesu) successfully completed the tests on Hoodi, allowing for transitions without crashes or memory issues.
-
@jasoriatanishq (@NethermindEth) is starting to work on Binary Tree implementation.
-
@gballet (@go_ethereum) is working on merging more code into Geth, aiming to perform more tests and replays for the testnet
2. EIP4762 Updates
- @gballet presented an update on EIP4762, explaining a proposed change to how system calls interact with witnesses. If a call is a system call, nothing should be recorded into the witness, simplifying the behavior.
3. BloatNet Updates
- @CPerezz19 shared that syncing at 2x mainnet size for state were conducted. There were some issues primarily due to peering. Only Besu and Geth were able to sync as of now. Future goals include incorporating more syncing metrics and launching compute-based benchmarks.
4. Blake3 vs. SHA256 in Geth
- @gballet discussed a pushback from Gary in the Geth team regarding merging Blake3 in Geth as there isn’t a reliable release in Golang. The teams have concluded that SHA256 would be used for the initial testnets until a formal decision is made at the EIP level.
5. State Expiry Pruning Benchmarks
- @ngweihan_eth presented benchmarking results for “naive pruning” in Geth, focusing on the snapshot layer to evaluate the effectiveness of state expiry. The results showed significant reductions in snapshot size (81.3%) and decent performance gains in state read and DB compaction time.
Call #40: August 11, 2025
1. Team updates
- @gballet @gabrocheleau (@StatelessEth/@go_ethereum): several stateless PRs merged in Geth; next up is transition logic and binary-tree integration.
- @CPerezz19 (@StatelessEth). Async update done by Guillaume: Bloatnet now ~2× mainnet & started a testing doc and are keeping a registry of bloatnet cases.
- @kt2am1990 (Besu): in-memory binary tree integrated; node can compute binary-tree state roots (non-validating) and follow a local fork; simple Geth vectors validate; shadowfork transition experiments ongoing; perf work reduced transition overhead. Besu has validated simple Geth vectors and will consume more as they land.
- @jasoriatanishq (Nethermind): wrapped Verkle transition work; addressing perf/refactors; binary-tree work to begin after leave (in 2 weeks), timeline TBD.
- @ngweihan_eth (@StatelessEth): code-chunking analysis shows ~30% average byte access for 32-byte chunks; code-access opcodes boost locality. Findings: ~half of EOAs active for only 4–5 days; most storage slots touched once within a block. Analysis
2. New testnet
- Besu will lead the binary-tree testnet; aim is before month-end. A Docker image enabling testnet bring-up should be shareable in ~1 week (includes recent EIP hooks and gas adjustments).
- Geth is delayed by a state-layer rewrite; unlikely to lead this month but will follow once ready.
- Nethermind timeline to be confirmed on the next call.
- Cross-client note: align handling of system-address calls for witness behavior; verbal agreement exists, spec/doc edits pending, and Besu will wire this once finalized.
3. EIP-2926 (Chunk-Based Code Merkleization)
- EIP-2926 is being resurrected as a smaller, low-risk step toward fuller statelessness.
- Benefits: removes the effective code-size ceiling, enables chunk-level witnesses/caching, and mitigates prover-killer patterns (e.g., pathological
EXT*CODE*access). - Plan: target an early rollout (e.g., Glamsterdam); perform a tree transition for code (~10 GB scale, ~1 day) to demonstrate feasibility, and ship a first, smaller package of the stateless stack.
- Next: present the proposal, circulate the draft and gather client feedback.
4. Stateless Summit
- @gabrocheleau preparing a survey to tooling teams, RPC providers, wallets, and client teams to gauge interest, proposed contributions, and topics; also to collect speaker nominations.
- Devconnect Buenos Aires may skew app-focused; if core-protocol attendance looks light, we’ll consider alternate timing (e.g., ETHCC Cannes in March).
- Action: finalize and distribute the survey; consolidate responses and propose an agenda window.
5. Testing documentation
- @gballet (@StatelessEth/@go_ethereum): Binary-tree testing doc started: input/output examples and root-hash verification. Expand beyond basic leaf insertions to account+storage scenarios.
- Test registry maintaining a running catalog of cases.
Call #39: July 28, 2025
Call was skipped because of low attendance. Below are the async updates.
1. Team updates
- @gballet@gabrocheleau (@StatelessEth/@go_ethereum) are still working on filling test fixtures, running into issues with the Binary tree filling that remain to be addressed.
- @CPerezz19 (@StatelessEth) created metric proposals for Sync & Compaction (https://hackmd.io/@CPerezz/SkzDZmngT) and created scenarios & questionnaire (https://hackmd.io/@CPerezz/ryoMhzaLel, https://hackmd.io/@CPerezz/HkZlj_jIgg) - Planning to review with teams (ETA Aug 1st 2025).
2. Upcoming testnet
- Postponed to next meeting.
3. Bloatnet update
- Ran into potential issues with Erigon and Besu. Erigon has identified the write amplification bug and are working on a fix.
- Besu suffered from bad peering, but this seems to have been solved.
- After a 1k block reorg caused by a wrong version of Besu, we are bloating again.
- Potential upcoming Bloatnet name change.
Call #38: July 14, 2025
1. Team updates
- @gballet @gabrocheleau (@StatelessEth/@go_ethereum) is working on filling test fixtures for Binary Trees, starting with binary-tree genesis and will then proceed with conversion testing.
- @kt2am1990 (Besu) is close to finalizing a working in-memory binary tree, while Geth faces delays due to a complete state layer rewrite. Should have an implementation ready to consume tests within a few days of work.
- @ngweihan_eth (@StatelessEth) is building a State Indexer project and presented code chunking analysis.
- @CPerezz19 (@StatelessEth) is working on witness updating and bloatnet progression.
2. EIP-4762: Witness addition rules
- Felix Lange raised concerns about the definition of system contracts in EIP-4762. The group agreed to revise the EIP to base witness rules on system calls (from specific addresses) instead of system contracts, reducing maintenance burden. Felix will update the EIP accordingly.
3. New testnet
- Besu team expects readiness for a binary tree testnet in about a month, while Geth is delayed due to a state rewrite. Agreement to proceed with a Besu & Nethermind-only testnet, breaking with the usual Geth-first approach. Timeline for Nethermind is uncertain, to be confirmed in the next call.
4. Bloatnet update
- Bloatnet has reached 1.5x the mainnet state after resolving RPC issues. All clients completed a first round of syncing tests. This round might have uncovered a pruning bug in Erigon, to be confirmed. Next phase will target 2x mainnet state, focusing on compaction and worst-case scenario testing.
5. Code chunking analysis presentation and EIP proposal
- @ngweihan_eth (@StatelessEth) presented analysis of 32-byte code chunking, showing a 30% average byte access ratio. Code access instructions significantly improve access ratios. The group discussed experimenting with different chunk sizes (e.g., 16 bytes) for efficiency. Wei Han will update the analysis and publish a dashboard.
Call #37: June 02, 2025
1. Team updates
- @ignaciohagopian (@StatelessEth): has kept working on adding more zkEVM coverage in
execution-spec-tests. He mentioned that these tests are not only trying to trigger worst-case scenarios but also build a foundation to reevaluate potential gas cost changes for zkEVMs. - @gballet (@StatelessEth/@go_ethereum): has finished the Binary Tree implementation with spec tests passing, and has been working on filling existing
execution-spec-testswith this new tree so other clients can have a larger set of tests to compare implementation correctness. It has also continued working on the Python-ification of EIP-4762 using received feedback. - @CPerezz19 (@StatelessEth): has been working on spamoor use-cases for state bloating, and preparation work for BloatNet, which was presented later in the call.
- @kt2am1990 (Besu): has been refactoring the Besu’s codebase to support shadow forks in general, not only for Hoodi. Also, he has been working on adding support for block creation, which surfaced some performance problems related to Verkle Trees. Since this tree was designed as abandoned, it has decided to ignore them and prepare for the next shadow fork to use Binary Trees.
2. Leaf-level state expiry (EIP-7736) effectiveness
@ngweihan_eth presented his work on the effectiveness of Leaf-Level state expiry. The presentation slides provide an excellent summary of findings, which can be found here.
After the presentation, there were some discussions:
- @gballet asked if there is any intuition on how raising the gas limit would affect the total active state of the network, or its relationship with worst-case scenarios. @ngweihan_eth mentioned that theoretically, the worst case is that all gas is used to touch as much state as possible within the state expiry epoch, so the active state is very big. On a more practical note, it is helpful to keep an eye on how raising the gas limit might change the data access patterns for many use-cases, for example, ERC20 contracts. Also, the state expiry period could be adjusted to 6 months instead of the usually assumed 1-year period.
- @CPerezz19 asked if it is possible to distinguish what kind of data is being expired, such as account vs storage data. @ngweihan_eth mentioned this isn’t possible. This is because unified tree designs don’t have extra information to provide semantics on leaf-level data. He noted that adding a marker could also help fix some revival transaction validation challenges, or consider not expiring account data, but only contract storage. More thought should be put into this since there might be some tradeoffs.
- @ignaciohagopian mentioned that in his previous research, he found that heavy mainnet usage of Solidity hashmaps in a unified tree was pretty unfriendly with state expiry. Hashmaps spread data over the tree space, creating many stems with only one value. @ngweihan_eth shared that he has also been thinking about this and found that many of these single values should expire, so at least at the value level, we can still make a big number of deletions. Still, it would be useful to dig deeper into checking how many of the unexpired stems only contain one value.
3. BloatNet initiative website
@CPerezz19 presented the release of the BloatNet website, which contains full details about the initiative’s motivation and goals. Additionally, it contains the metrics to be gathered and the potential attack vectors to try bloating the Ethereum state size as much as possible. After the first version of this devnet runs, this website will contain all the findings that can help motivate any protocol changes to prevent excessive state growth and understand the implications of gas limit increases on network robustness.
He mentioned that feedback has already been received from Geth, Besu, and Erigon, which is helpful since they’re the main network actors who will benefit from the findings. Any other core developer or community member is welcome to collaborate — the three main sections of the website (Metrics, Attack Vectors, and State Bloat) contain forms you can fill out to suggest more metrics, bloating strategies, or any useful idea.
Call #36: May 19, 2025
1. Team updates
- @ignaciohagopian (@StatelessEth): has worked on the zkEVM benchmark suite to assess the performance on zkVMs for L1 block proving. He will present this work in a future SIC to explain it further.
- @gballet (@StatelessEth/@go_ethereum): has been working on merging more pending PRs into geth, rebasing the current default stateless branch on top of Pectra, phant compilation to RISCV32, remaining spec differences with Geth Binary Trees implementation, and an EIP-4762 spec rewrite that was presented later in the call.
- @GabRocheleau for @EFJavaScript: has made progress in passing the conversion tree execution spec tests and helped review the rewrite of EIP-4762 draft PR.
- @kt2am1990 (Besu): has worked in a Hoodi state tree conversion that was later presented in more detail in the call. Thomas from his team will also start working on a Binary Tree implementation for Besu.
- @lfmpinto (Besu): worked on enhancing tx/block tracing to include the witness state at each opcode execution event — this is the related PR.
- @jasoriatanishq (Nethermind): has been progressing in passing all existing tests in the rebased version on top of Pectra. He plans to reproduce Karim’s work in the Hoodi testnet and work on a Binary Tree implementation.
- @CPerezz19 (@StatelessEth): has been working on including more scenarios into the spamoor tool and coordinating with the Nethermind team on how to prepare the launch of BloatNet. He has also been contacting wallets and dapps to understand their thoughts on strong statelessness and share new ideas to see if users providing witnesses can be incentivized at the protocol level.
2. Hoodi state tree conversion
@kt2am1990 presented his work migrating the Hoodi state tree in the live testnet using the current Overlay Tree + block-by-block state conversion EIPs.
The presentation can be found here and can provide a nice summary of the talk, but as some general remarks:
- It used a Nimbus client as the CL to connect to Hoodi and two Besu nodes for the task.
- Two Besu nodes were used as a quick way to have preimage resolving for the tree conversion.
- The timestamp where the conversion starts is hardcoded today, but other ways of providing this value can be evaluated in the future when more clients join a similar setup.
- The total conversion progress took 13 hours, according to Hoodi’s slot time duration.
- Previous run attempts allowed for detecting problems, including performance, chain reorgs, and state rollbacks. After the fixes, a successful run was possible.
- Future steps could cover performing the same work in bigger networks like Sepolia or Mainnet.
After the presentation, there were follow-up discussions:
- @gballet agreed it would be helpful to have more clients join the same effort so the resulting state roots can be further verified. He also mentioned it would be helpful to see if it would be possible to try other code paths, such as block building.
- @gballet asked if there were available metrics regarding the pre- and post-state size, which could be interesting. @kt2am1990 mentioned that he will take a look and share offline.
- @gballet asked if there was more insight into the conversion speed, and @kt2am1990 mentioned the extra RPC influenced these calls for preimage resolving. The node will have the preimages in future versions, and these extra RPC calls can be removed.
- @ignaciohagopian mentioned that reorg-like tests don’t exist yet since it is pending that the testing framework can support them, but it is planned to do it eventually.
- A variant strategy for checking state roots between EL clients is to export an existing chain, agree on the conversion timestamp, and let clients run the migration “locally” and compare results. This could be easier than shadow-forking a live testnet.
More EL clients will be jumping into running these scenarios to gain more confidence about state root calculations (and thus, the correctness of the EIP implementation).
3. EIP-4762 revamp
@gballet presented a rewrite of EIP-4762 with a more Pythonic style, aligned with the more modern styles of protocol changes specs. This rewrite is the first draft that @GabRocheleau and @lfmpinto reviewed.
The EIP rewrite helped identify implementation bugs in Geth, such as accessing bytecode outside the defined bytecode for a contract (i.e., a PC greater than the contract size without accessing valid bytecodes in that code-chunk). Other clients will double-check how they have implemented this particular border case to see if there is already a consensus bug issue.
Apart from rewriting the original EIP, this new version also aims to cover the atomicity changes discussed in previous SIC calls and EIP-7702 considerations pending in the current specs. The draft must still resolve how warm costs are charged correctly, checking CALLCODE witness rules, and other quirks. Still, there will be further iterations after getting feedback from reviews.
After the presentation, there were further discussions:
- @GabRocheleau asked about the plans for Binary Trees and the current EIP. @gballet said that at this point, it seems clear that the current plan is going with Binary Trees, but we will still use Verkle for short-term efforts on Hoodi state tree conversion. Whenever the next stateless devnet happens, it will use Binary Trees (probably around Q2/Q3). EIP-4762 will be used as is for Binary Trees since it should be compatible with the EIP assumptions about the underlying tree. There might be pushbacks and potential changes, but it should make sense overall.
- @jasoriatanishq asked how fast we’ll start using Binary Trees in the upcoming work, since in the next steps, EL clients will try reproducing @kt2am1990 work on Hoodi. @gballet confirmed that this is the plan (i.e., keep testing the conversion with Verkle) and Binary Trees will be used first in a less complex context, such as a fresh devnet.
4. Forking rules for state tree conversion
@GabRocheleau raised a point on how the forks would work for the state transition, particularly regarding how EL clients decide on expectations on witness in the block and/or the Overlay Tree functioning.
@gballet mentioned that Geth works by only expecting a single fork, and keeping track of the state conversion logic initialization and finalization events to decide on those particular points. @GabRocheleau found this clarification helpful and suggested that it be explained better in the specs. @gballet agreed we can do that.
Call #35: May 5, 2025
1. Team updates
- @ignaciohagopian (@StatelessEth): published an article revisiting bytecode chunking solution space and started helping on zkVM benchmarks.
- @gballet (@StatelessEth/Geth): worked on many upstream PRs into Geth, began rebasing the stateless branch on top of Pectra, and is preparing for a rewrite of EIP-4762 with a more Python-like style, which will also include EIP-7702 updates.
- @CPerezz19 (@StatelessEth): is preparing to launch a devnet focused on aggressive state-growth; scripted spam scenarios that maximise “gas-per-byte” expansion and started prototyping a mainnet replay strategy to reach 2-4× state size.
- @jasoriatanishq (Nethermind): finished the Pectra rebase and will then work on integrating the tree conversion. He also plans to work on the implementation of the Binary Tree EIP.
- @kt2am1990 (Besu): rebased Verkle on Pectra and tested the conversion on Hoodi. While doing so, he identified some bugs and performance issues that are being fixed. Thomas keeps working on stateless verification.
- @GabRocheleau for @EFJavaScript: working on passing all the tree conversion test vectors, generalizing the conversion to any target tree, and doing other architectural adjustments.
2. BloatNet state-growth testnet
Note: the call recording refers to this devnet as FatNet but it was later renamed to BloatNet.
@CPerezz19 explained the goal of BloatNet: replicate Nethermind’s idea with PerfNet but focus on state size growth and its implications for EL clients. He shared a collaborative document to identify valuable metrics to gather.
@sophiagold suggested including snap-sync metrics, and @CPerezz19 mentioned it is useful but requires chatting with Pari to figure out how to do this correctly, since it might have some networking assumptions.
@gballet mentioned that EL clients already have a cap on the number of connected nodes, so we might be able to simulate this realistically. Additionally, he mentioned that some transaction load (and proper access patterns) should be happening on the chain to test the healing phase correctly.
3. EIP-7748 – special-account conversion rule
A follow-up discussion clarified some confusion in the last SIC regarding custom rules in EIP-7748 regarding not converting some data.
@gballet confirmed that the accounts previously described in EIP-7748 don’t exist on mainnet. The new proposed action targets accounts described in EIP-7610: accounts with zero nonce, empty code, non-zero balance, and non-empty storage. There are accounts satisfying this condition on mainnet, and it will be helpful if we can clean them up during the conversion. The intention is to keep the invariant that if an account has non-empty storage, the nonce is greater than zero.
It was pointed out that this rule doesn’t conflict with EIP-7702, since any activated delegation implies an increase of the nonce, thus stopping the nonce==0 condition of the rule.
EIP-7748 was already updated with this new rule, so EL clients are expected to update their implementation. This also means that execution-spec-tests should cover this new rule.
4. EIP-7702 – delegation removal semantics
@ignaciohagopian wanted to discuss more precisely a topic tangentially touched on in the previous SIC call: which is the proper action in the new tree when an EIP-7702 delegation is removed?
He proposes that, apart from updating the code-size and code-hash to zero and empty, we must also clear the delegation indicator. He argues that, although a removed delegation can be indirectly detected by checking the code size or code hash, it would leave the tree in an inconsistent state. If someone only looks at the first code chunk, they might see a delegation without effect since it is also forced to check the code-size/code-hash.
After discussing the increased gas cost, @gballet and @kt2am1990 agreed that clearing the delegation indicator is correct. Nobody else opposed the decision. This decision will be materialized in the upcoming EIP-7702 updates in all stateless-related EIPs.
5. EIP-4762 – atomic witness charging
Some SIC calls ago, @gballet proposed a change for EIP-4762 where additions to the witness corresponding to a single operation have atomic gas charging, which means they don’t generate partial witnesses.
He implemented this for Geth and feels that this is a change worth confirming. @jasoriatanishq was initially doubtful about this change, but now has a neutral opinion. @gballet also mentioned that most tests pass, but only 99 fail. This is likely expected since it is a spec change. @ignaciohagopian confirmed that some tests are expected to fail, and he can help identify which ones should, so we know which is a good stopping point for tests to pass.
Additionally, @ignaciohagopian said this proposal should be written in the EIP — the plan is to include it as part of the more general EIP-4762 rewrite that will happen soon.
6. Access-lists interaction with 4762
@ignaciohagopian noticed that the current EIP-4762 spec doesn’t mention any effect on currently available access lists. In particular, he mentioned an example where a currently warmed-up storage slot via access lists would have a more expensive gas cost after EIP-4762. This means it will probably break contracts that rely on access lists for proper functioning.
@gballet did some history exploration on the previous versions of the EIP and found that an old version mentioned access lists but was only related to their serialization format and not gas cost impacts.
@ignaciohagopian proposed two options. The naive one is processing the access list and including the accounts/storage-slots as part of the witness, which can cause witness bloat if those aren’t accessed. The other variant is EL clients must always consider access lists before doing any branch/chunk cold charging, which avoids the witness bloat if elements in the access list are never accessed.
@gballet said that something around those lines could work, and suggested doing an EIP-4762 PR concrete proposal to clarify this topic and discuss it again in a future SIC to make a decision.
Call #34: April 21, 2025
1. Team updates
@ignaciohagopian from @StatelessEth: worked on a newly published Tree Shape page in the book, progressed on a new tool to analyze 4762 mainnet impacts (gathering metrics while doing that), and is finishing some research doc on bytecode chunking and a book page for the 32-byte code chunker.
@GabRocheleau for @EFJavaScript: I made progress on the tree conversion code and plan to start running existing execution-spec-tests to check the correctness of the implementation.
@gballet from geth/@StatelessEth: continued working on merging tree conversion logic into geth master. He also published a Holesky shadowfork page in the stateless book, which explains how to easily run geth in devnet mode using Holesky state.
@jasoriatanishq for Nethermind: has been wrapping the tree conversion implementation, now passing all tests. He is also working on rebasing the working branch on Pectra.
2. EIP-7612: follow up on code conversion when touching an account
The discussion focused on EIP-7612’s behavior in specific scenarios, namely:
- When the storage slot of a contract is written to.
- Whether code should be converted to the new tree when account data (e.g., balance) is written.
In the first issue, @gballet initially had concerns about the difficulty of implementing the change for geth. However, upon further investigation, he concluded that the change was not as problematic as initially thought. Given the support from other EL client core developers, the decision was made to convert only the written storage slot and not the account data.
In the second issue, the group had previously decided that careful calculations regarding the worst-case write load were necessary if code conversion was also implemented. @gballet presented the calculations, and it was confirmed that the change was unsafe and therefore could not be made. This conclusion aligns with EIP-7612, so no changes to the specification are required.
3. EIP-7612: EIP-7702 code-mutation implications
During discussions, @ignaciohagopian mentioned how EIP-7702 introduces a new scenario where an account’s code might need to be converted as part of EIP-7612 before tree conversion is activated.
When EIP-7612 is active and a transaction with a 7702-delegation is executed, an an EOA’s code is considered modified, i.e., the bytecode is modified. Since the Merkle Patricia Trie is considered read-only, the delegation bytecode should be written in the new tree. Participants agreed that this is the correct behavior for EIP-7612.
@gballet also raised the scenario where an EOA with an existing delegation decides to remove it. Currently, the new tree API doesn’t support deletions. The conclusion reached was that the corresponding code-chunk of the delegation would be written with 0x00 bytecodes. The removal of the delegation would be signaled by codeSize and codeHash having values zero and empty-hash, respectively (although the code-chunk would still exist in the tree since leaf deletions aren’t supported).
These conclusions will be included as part of EIP-7702 impact on stateless EIPs.
4. EIP-7748: empty accounts conversion rule
@ignaciohagopian proposed simplifying EIP-7748 by removing the current rule of not migrating empty accounts with storage data. The original intention of this rule in the EIP is to finish cleaning up existing accounts during the tree conversion. However, considering that EIP-7523 claims no existing instances are present in mainnet, this rule could potentially be removed, lowering the complexity of the tree conversion logic..
@gballet noted that while EIP-7610 claims there are accounts with zero nonce, zero code length, and non-empty storage, it isn’t clear if these cases include any account with zero balance.
The decision was made to verify with a synced full node whether any empty accounts with non-empty storage still exist in the mainnet, after which removing the rule from EIP-7748 could be considered.
5. EIP-7748: tree conversion logic position in block execution pipeline
During tree conversion test writing, @ignaciohagopian noticed that geth’s tree conversion logic was triggered after block transaction execution, contrary to EIP-7748, which describes it occurring beforehand. He explained this shouldn’t be an issue theoretically, as any tree conversion writes can be overridden by block execution writes, and tree conversion writes are independent of transaction execution effects.
An open question was posed to participants about potential relevance of both orderings. No compelling reason favouring one order over the other was identified — the exact positioning is not considered relevant at the specification level, allowing EL clients to determine the placement as an implementation detail.
6. EIP-4762: CALL new account cost and FILL_COSTs
During the meeting, @ignaciohagopian presented a potential mispricing issue with FILL_COSTs in EIP-4762. The presentation, supported by slides, explained that after packing account fields into BASIC_DATA, the FILL_COST might be too low. This allows creating a new account with a value-bearing CALL costing approximately half the gas compared to the current mainnet cost of 25,000. Additionally, creating a new storage slot under EIP-4762 would also be approximately half the cost compared to mainnet.
The meeting concluded without a decision on how to adjust the current FILL_COST gas cost of 6,200. Further discussions are necessary to understand the potential implications of repricing on other aspects of writing new state.
Call #33: April 7, 2025
1. Team updates
@ignaciohagopian from @StatelessEth: worked on new execution-spec-tests conversion tests, a document shared with @techbro_ccoli regarding tech debt in the testing framework, and also shared a document about EIP-4762 worst-case blocks.
@gballet from Geth/@StatelessEth: has been working on a Binary Tree implementation for geth, where the next steps are running the official test vectors to check correctness. He also has been working on merging the tree conversion logic into mainnet Geth.
@CPerezz19 from @StatelessEth: has been working on a document to be shared soon on the relationship between stateless and FOCIL, investigating potential incompatibilities/challenges and symbiosis between them. Some findings might be discussed in future SIC calls.
@kt2am1990 for @HyperledgerBesu: has been working on the tree conversion, fixing some problems found while running the tests shared by @ignaciohagopian. All tests are passing now.
@jasoriatanishq for Nethermind: has also been working on tree conversion, with most tests passing. It is also working on rebasing Nethermind Verkle implementation on top of Pectra.
@GabRocheleau for @EFJavaScript: he couldn’t make much progress on the tree conversion logic, but he’s planning to resume that work in the upcoming weeks.
@techbro_ccoli from STEEL: has finished the long overdue pending rebase of execution-spec-tests branch for stateless and is planning to start working on the items mentioned in @ignaciohagopian testing-framework tech-debt document.
2. “A Protocol Design View on Statelessness” presentation
@_julianma from the EF RIG team presented a recent Ethresearch post about a general view of statelessness from a protocol design perspective. Both this research post and presentations are highly recommended. The slides are available here.
Summary of the Q&A after the presentation:
- @gballet questioned whether dapps or wallets would be willing to host the state. @_julianma expressed uncertainty about applications taking that responsibility as the optimal solution. @gballet mentioned it would be a good line of work to continue exploring further by contacting dapps and wallet providers.
- @MorphNetrunner from the Portal Network team asked if the Portal network was considered for witness creation. @gballet mentioned that Piper might prefer to wait before promising the network could provide this capability.
- @sophiagold asked if the mentioned out-of-protocol state-expiry rules can help with the state growth problem or any of the drawbacks of known state-expiry solutions, such as address space expansion. @_julianma said that probably not, but maybe through this optimization problem, framing new avenues could be discovered.
- @ignaciohagopian shared a point from @soispoke (not present in the call) about how transaction witnesses could be resolved in private mempools by actors other than the transaction sender. The challenge remains for high CR guarantees using the public mempool.
3. EIP-7612: Contract’s code conversion
The current EIP-7612 proposes that an existing contract code will never be converted to the overlay tree outside the tree sweep. @kt2am1990 mentioned this could complicate Besu implementation, thus raising the point if we can reconsider this choice.
@gballet raised the point that this can complicate the implementation but also raised the concern about witness blowup if the existing contract code is to be converted, which can be inconvenient.
@jasoriatanishq mentioned that before, we had considered not including execution witnesses in blocks before the full tree conversion is done, which implies execution clients might need to full sync from the snap sync syncing point up to that moment. @gballet mentioned that including partial execution witnesses might be preferred by the geth team to assist in having a better syncing strategy than full sync. Since there’s no consensus around this topic, we might touch on this again in future SIC calls.
Apart from this potential concern, @ignaciohagopian noticed a similar drawback which is independent of that decision: execution clients still need to do Overlay Tree writes even without partial execution witnesses, so a malicious block builder can build a block that (indirectly) converts as many 24KiB contracts as possible resulting in a very high load for clients since they need to do a lot of insertions. @gballet shared some quick math on this topic, saying this might not be a concern, but @ignaciohagopian mentioned it doesn’t seem to match his intuition.
After checking his assumption offline, it was confirmed by @gballet that the extra leaves would amount to ~1.8M for a 36M block, which is a good reason not to do that. To be continued in the next SIC
4. EIP-7612: Account Header
In the last call, we previously discussed whether, during the Overlay Tree phase before the tree conversion, a transaction only writing to a storage slot triggers the conversion of the account. Considering how geth works, this is the case since the change in storage root is understood as an account basic data change that triggers the mentioned conversion.
In the previous call, there was some slight consensus to keep this behavior, but now that more EL clients have run the tests, this topic has been re-discussed.
@jasoriatanishq mentioned he prefers only to move the storage slot without the account data. @kt2am1990 mentioned migrating the account isn’t a big problem compared to the previously discussed code conversion rule. @gballet dived into the technicalities of doing it in geth, which could be challenging, and he will be in contact with @jasoriatanishq to understand better how this is done in Nethermind.
This topic is closely related to the previous contract code discussion, so we will continue discussing both in the next SIC call, considering any other off-topic talks during the next two weeks.
5. Next call agenda
The call ran out of time to discuss the last two agenda items, which will be rolled over to the next SIC call.
Call #32: March 24, 2025
1. Team updates
@ignaciohagopian from @StatelessEth: has been working on EIP-7748 execution spec tests in the context of the previous decision on focusing stateless efforts in gaining confidence on EL clients implementations for the tree conversion.
@jasoriatanishq for Nethermind: is finalizing the tree conversion implementation in Nethermind and planning to run the execution spec tests next week.
@kt2am1990 for @HyperledgerBesu: made progress on general stateless implementation tasks. In particular, he has a preliminary version of the tree conversion, which passed preliminary execution spec tests and uncovered some bugs.
@GabRocheleau for @EFJavaScript: he started the tree conversion implementation and will probably be able to execute the provided tests in one or two weeks.
2. Tree conversion (EIP-7748) testing planning document
@ignaciohagopian presented a new document describing the strategy and test cases for tree conversion testing.
At the top of the document, a set of bullets quickly describe the main reasons we need to plan test cases to cover in the tests and different stages of testing, including execution spec tests, running devnets with synthetic or testnet/mainnet data, and finally shadow forks of testnets/mainnet.
He continued to present at a high level the different buckets of designed tests, which include testing:
- Non-partial account conversion
- Partial account conversion
- Code-chunk stride accounting
- Special accounts
- Conversion ending
- Modified accounts
- Blocks txs execution with writes overlapping conversion units
- Access partially converted contracts
- Reorgs
The document uses emojis to signal which tests are already created, pending, or require testing-framework changes to be supported. For more details, refer to the document.
The new fixtures will be shared in the matrix group for EL clients. EL clients should remember that failing tests can have a decent probability of getting bugs in EIP-4762, so it makes sense to share as early as possible if that’s the case for further inspection. After at least one client passes all the tests, failing tests probably signal a bug in your EL client.
Regarding potential geth bugs, @gballet shared that geth has a known bug affecting the Holesky shadow fork run but probably not the testing filling mentioned. The bug is known and can be worked around, but if anyone is trying to build a devnet or shadow fork using the current version, please wait until the bug is fixed.
3. Indirect account header conversion when writing storage-slots
@ignaciohagopian raised a subtle point on how geth works by describing the following scenario:
- The overlay tree EIP is activated.
- A tx writes to a storage slot in a contract.
Under this scenario, as described in EIP-7612, the write done in the storage slot should happen in the new tree (i.e., overlay tree). But there’s an extra write also done in the new tree: the contract account header.
At first sight, this might be surprising since no actual write happens in the account header, but it is coherent. Currently, under only Merkle Patricia Trie’s (MPT) assumptions, a write in any storage slot means the storage root of the account would be updated. This marks the account header as dirty, which has also been converted to the new tree. The subtlety is that the account header didn’t have any real data update since the storage root isn’t part of the new tree design, and it also doesn’t make entire sense since the MPT is frozen.
The bottom line question is if this makes sense for all EL clients or if we might want to change the behavior, since another reasonable option is not doing this indirect conversion.
The consensus from @gballet, @g11tech, and @kt2am1990 seems to be that keeping the current behavior is OK. @ignaciohagopian mentioned if EL clients are unsure of how their clients behave, this will be apparent when they run the execution-spec-tests since they’ll disagree with geth, at which point we can re-discuss the topic if needed.
4. Testing framework: Preimages
Some days ago, when @kt2am1990 was testing some of the first available tests, it was considered that the fixtures could contain a separate field with the MPT preimages required for EIP-4762 logic.
@ignaciohagopian explains that geth works today by automatically recording the MPT preimages when it ingests the provided fixtures pre-state. He believes we shouldn’t blow up the testing framework with extra fields if EL clients can derive it from existing data.
@techbro_ccoli from the testing team made it even clearer that you can interpret the preimages from the pre-state, which should be enough compared to a more explicit field of preimages. In summary, we won’t add the preimages as a new field in fixtures, and clients should continue to record them as they ingest the provided fixture pre-state.
5. State Expiry discussion
@g11tech raised a topic outside the agenda that is still related to the tree conversion topics. Can we reuse the code of the transition to implement state expiry?
@sophia provided more historical context and confirmed that trying to achieve expiry by using one tree per epoch was very complex since it requires introducing address space extensions and has high UX friction. She provided the following links, which dive deeper into this topic: a potentially underexplored idea that could be a viable solution and a summary from Vitalik from some time ago about state expiry.
@ignaciohagopian mentioned that we should try allocating this topic to a future SIC agenda so we have time to continue the discussion if needed.
6. Post-quantum Verkle Trees variants
@CPerezz19 wrote a document that summarizes the main benefits of the current Verkle Tree design and how it compares with other presented alternatives. In particular, it explores potential variants that address the post-quantum weakness of the current design.
He has been talking with many experts in the field and found out there’s active interest in the topic. This might signal an underexplored topic, meaning there might be viable PQ variants for a Verkle Tree design.
The next step is to get more cryptography experts involved in the presented document to have feedback and potentially do some benchmarks to confirm if any of these variants could be a feasible contender to be proposed.
Future SIC calls will continue to discuss this topic since we need to give time for more people to chime into Carlos’s work and provide feedback.
7. EXTCODECOPY behavior when targeting system contracts
@gballet raised whether doing an EXTCODECOPY of a system contract should include system contract code chunks in the witness.
This creates tension with the current EIP spec, which mentions not adding system contract bytecode with few exceptions. The argument behind the current spec is that stateless clients have all system contract code baked into their implementation, so adding this information in the witness is wasteful. This definition would force geth (and potentially other clients) into extra complexity in detecting which cases executed code should be included in the execution witnesses, which can lead to bugs (compared with clients doing direct storage access for system contract implementations).
Both @g11tech and @kt2am1990 agreed that adding the system contract bytecode to the witness for these cases would be fine. The remaining task is opening a PR and changing the spec to clarify this newly decided behavior.
Call #31: February 24, 2025
1. Team updates
@ignaciohagopian from @StatelessEth: worked on pre-image file generation and writing the Ethereum stateless book, both of which were shared later in the call.
@gballet for @go_ethereum: stateless book reviewing and digging into how a proving system for binary trees would look like.
@jasoriatanishq for Nethermind: started rebase on Pectra for the next devnet.
@kt2am1990 and Thomas for @HyperledgerBesu: made progress on Besu working in stateless mode around state reconstruction and proof verification. Also, starting to work on the state conversion EIP.
@GabRocheleau for @EFJavaScript: merged the Binary Tree implementation with some tests from the spec and some extra ones. Now working on writing better documentation and the client state manager for this tree.
2. Preimage file generation
@ignaciohagopian presented the work published in Ethresearch some days ago.
The presentation can be viewed in the video recording between timestamps 04:46 and 31:32 (~27 min).
The slides can be accessed here.
Points touched after the presentation:
- Gottfried suggested we make each entry in the preimage file 32 bytes instead of [20-bytes || 32-bytes]. This could simplify cursor management in clients for reorgs since moving back only depends on the sweep stride and not specific block details. The file compression could automatically hide the extra overhead.
- @gballet said that for geth, things might not be simplified much. Gottfried highlighted that the proposal can lead to a more straightforward implementation despite being doable.
- Gottfried raised another point: If we don’t go with the CDN path and have to chunk the preimage information, we’d have to think about verifying each chunk independently, which can introduce more complexity. @gballet mentioned we can solve this with a two-pointer header. Depending on the distribution mechanism we decide on, we might have to dig deeper into this, or we can ignore it.
3. Ethereum Stateless Book announcement
@gballet did a quick overview of the recently published Ethereum Stateless Book. Both @ignaciohagopian and @gballet worked on this first version.
The book provides a complete picture of many angles about going stateless, such as:
- Motivations
- Target trees
- BLOCKHASH state
- Gas remodeling
- State conversion
- Use cases
- Resources
- Development
Ignacio mentioned that the book is open source, and anyone is invited to collaborate.
4. Multi-client State Conversion
@gballet shared that there are current discussions with the research team about the right path forward regarding statelessness to avoid potentially repeating what happened with Verkle Trees.
He highlighted that getting more confidence in how fast clients can be ready for the state conversion can be decisive. He thinks it’s worth inviting more EL clients to work on it so we can show that the state conversion has a low risk.
Reaching a milestone where multiple clients go through a complete conversion of state without consensus bugs might be a more important goal than a new devnet with features that we’ve discussed in previous SIC calls.
@GabRocheleau asked if we should work on the conversion EIP with Verkle or Binary, and there seems to be an agreement to do it with Verkle. The target tree isn’t important for the goal since the conversion is tree-agnostic. However, doing it with Verkle is easier for clients since most of them already have the implementation ready compared to Binary Trees.
@ignaciohagopian mentioned that he would be working on execution-spec-tests for the conversion so clients can test their implementations faster than launching devnets. There will be collaboration on this with Spencer from the testing team.
@gballet raised a point about a potential confusion between the data migration order in the EIP and the preimage file, but the discussion will continue offline. This point may be resumed in further SIC calls, but currently, no action is needed.
Call #30: February 10, 2025
1. Team updates
@GabRocheleau for @EFJavaScript: The Ethereum JS team has developed an early implementation of binary trees to serve as a testing ground for future developments.
@kt2am1990 and Thomas for @HyperledgerBesu: The Besu team has been working on some code refactorings to allow stateless execution of blocks, in particular, only relying on chunkified code chunks for EVM execution. Additionally, the implementation of block-proof verification is being finished.
@jasoriatanishq for Nethermind: No updates at the moment.
@ignaciohagopian from @StatelessEth: drafted the Binary Tree EIP, benchmarked the out-of-circuit performance of hash function candidates, and started working on some documentation projects that will be released soon.
@gballet for @go_ethereum: have been upstreaming stateless related changes to geth and collaborating on Binary Tree spec efforts.
2. Binary Tree EIP
@ignaciohagopian presented an overview of the Binary Tree EIP.
The underlying motivations for a Binary Tree EIP are:
- Concerns about quantum computers becoming a real threat due to breakthroughs last year.
- Verkle Trees introduce non-quantum-safe components into the protocol, which is in contrast to new efforts, e.g., new research on signature aggregation for CL, and others.
- Depending on the estimation for quantum computers becoming real, the return on investment of Verkle Trees might not be worth it.
- SNARK proving systems performance improving rapidly, making it more viable to use them for proving pre-state for blocks.
- Jumping directly into a potential final tree: deploying Verkle Trees means we’ll have to do a tree conversion again for quantum. Doing a Binary Tree has higher changes than Verkle in becoming the final tree potentially avoiding further tree conversions.
Regarding the design:
- It pulls many ideas from Verkle Trees EIP
- Data encoding aggregates accounts data in stems.
- The same applies to storage slots and code chunks.
- Code chunkification is the same as Verkle but with minor tweaks.
- The implementation is much more straightforward than Verkle since it only relies on hash functions, so we don’t have to introduce new elliptic curves or similar structures.
- Python spec implementation.
- The hash function for Merkelization:
- The current proposal uses Blake3 as a first proposal since other hash functions, such as Poseidon2, aren’t considered safe today. EF research is actively working to assess its security more formally.
- Poseidon2 is probably the best candidate since it’s an arithmetic hash function that is very efficient for proving systems.
- Given a full implementation of a Binary Tree with Blake3, if we decide to switch to Poseidon2, it would be a simple change, so this dilemma of whether or not to use Poseidon2 shouldn’t be a blocker to starting to implement it.
- The current proving performance for hash functions which aren’t Poseidon2 is still one order of magnitude far from what we need. Poseidon2 proof generation is already fast enough.
Question regarding the current viability of Verkle Trees vs. Binary Trees:
- @ignaciohagopian claims Verkle Trees have a low chance of being used.
- Depending on how the L1 scaling roadmap is defined, other changes, such as delayed execution payload, might even favor binary trees.
- It’s pretty hard to know this until it’s discussed in ACD, but call participants seem to agree that Binary Trees now have higher chances of being the right state tree switch.
Regarding future stateless devnets:
- The next devnet will still be Verkle since we only plan to implement EIP-4762 missing features. But further devnets probably will be Binary.
- Binary Tree devnets can start with Blake3 as the hashing function without proof. This can buy time until we decide on the security of Poseidon2 and proving systems. Since later switching the hash function shouldn’t have a significant impact, we aren’t blocked by this.
3. Atomicity in gas charging
@gballet explained a proposal from the geth team regarding how some operations in EIP-4762 should have other atomicity semantics. The motivation from the geth team is simplifying the implementation in their codebase.
The current way EIP-4762 works is that some operations that expect to add more than one leaf to the access events aren’t atomic:

Received feedback:
- @jasoriatanishq for Nethermind claims this change might make their implementation more complex.
- @ignaciohagopian from @StatelessEth raises concerns about whether this change would make the spec more complex since now atomicity in witness additions is something we must explain very well to avoid consensus bugs. Today isn’t required since any addition is expected to be atomic, and there’s no “group level” atomicity concept.
@gballet acknowledged these opinions but thinks the spec is unclear, and might plan to implement the proposed change in geth to confirm if this concludes it might simplify geth implementation or if this was just a wrong intuition. We expect to continue to discuss this proposal in further SIC calls.
4. Account version discussion
This is a topic raised by @gballet.
@ignaciohagopian starts by giving a summary of the motivation for this discussion:
- The current tree proposal has a
VERSIONfield. - There’re motivations to encode into the account stem, information to distinguish if the account is using EIP-7702 delegations and/or is an EOF account.
- The dilemma is between using:
- The
VERSIONfield in the account stem to signal if it’s a usual EoA, EIP-7702 or EOF account, or - Keep using
VERSION = 0and encode this information in the reserved bytes inBASIC_DATA.
- The
@gballet goes through further details about potential future use cases for VERSION and signals that it seems pretty clear that we shouldn’t use the VERSION field. @jasoriatanishq and @ignaciohagopian agree on the conclusion.
@ignaciohagopian gives a final summary:
VERSIONdescribes tree-level semantics, i.e., how to interpret the 256 values in the stem.- Account level identification is independent from the tree, which justifies not using
VERSIONfor this butBASIC_DATAreserved fields.
5. New stateless team public page and X account
@gballet shares two updates:
- stateless.fyi, a new website is a refreshed public explanation about Ethereum’s stateless benefits.
- A team X account was created, which people can follow to get updates about Ethereum’s stateless efforts.
Call #28: December 2, 2024
1. Team updates
@ignaciohagopian and @gballet for @go_ethereum: started working on EIP draft for binary tries. Also working on new execution spec tests from bugs that were found in latest devnet.
@g11tech for @EFJavaScript: been playing with devnet-7, and resolving some recently found issues.
@kt2am1990 for @HyperledgerBesu: Working on implementing the blockhash gas cost modification. Also implementing the proof verification. This will unblock some other stuff like Verkle sync (snap sync equivalent), and validating proof coming from the other client. Also working on optimizing stem generation by modifying how we call the Rust Verkle library.
2. Execution spec tests
Update from Ignacio, sharing v0.0.8.
After we previously launched devnet-7, we found a consensus bug with Nethermind. Debugged with Tanishq and found an edge case. Created a new test case to cover this. Idea going forward is that every bug we find in any devnet should result in a new execution spec test to cover it. Any new client that joins the next devnet will also be covered by these cases.
3. Preimage distribution and Portal Network
Piper from Portal Network joined to share some thoughts on preimage distribution with Portal.
Regarding preimage distribution for the Verkle migration: Piper mentioned that Portal can solve this, but probably isn’t the best solution. Portal is best for clients who want to grab a subset of the data on demand. With the preimage problem for Verkle, all of the clients would need to grab the full set of preimages. But there could be a “file-based approach” that could make sense in this case.
The file-based approach: S3 buckets being able to generate the file, and potentially having pre coded S3 buckets in clients that are already distributed. Has a predistributed trust model. Distributing big files like this from S3 buckets is a pretty straightforward approach. Alternative to S3 buckets, could use torrents.
Guillaume mentioned that Lukasz from Nethermind had previously indicated a preference for using an in-protocol p2p approach. But added that it seems clear that the CDN approach is the simplest and should probably go with that.
Next steps: make a spec on a potential format for the file.
4. State expiry
Hadrien from OpenZeppelin joined to share some thoughts on state expiry.
One related question that was discussed in Devcon: do we want to resurrect based on reads or based on writes?
Hadrien: most of the storage accesses are as you expect related to reading and writing. And so one question is whether a read would extend the lifetime of an extension or not. There are a few slots that are being read, but never written to. For example in the case of ERC-721, when tokens are transferred the slot will often contain a zero because nobody is allowed to take the token. And anytime there is a transfer of that token, in the current implementation it will write another zero to reset, even if old value is a zero, because its cheaper than trying to read. Depending on how state expiry works, there may be different cost model depending on whether there is a zero because it was never written to the state, compared to if a zero gets explicitly written.
This is where the approach of state expiry shown in EIP-7736 comes in. Han joined to share some updates on this front.
Han is currently working on implementing 7736, and the changes needed on the Verkle part are done. Still working on the geth part. Once we get all the components complete and integrated can hopefully have a devnet to start testing out the various scenarios.
5. Stateless Transactions EIP
Gajinder shared some of the latest thinking around changes needed to best support stateless clients.
One of the challenges is that stateless clients which don’t maintain any execution state would not be able to do any kind of local block building. This proposal is a partial remedy to this problem.
The basic idea is that with every transaction the transaction submitter will also have to submit an execution witness, and that execution witness will have a state diff + proof of the state diff. The execution witness would also bundle the parent state root, which is what a builder would look at to see whether it can include this tx in the particular block that it’s building.
Gajinder is currently drafting the EIP. Will have something to share soon.
Call #27: November 4, 2024
[no notes this week]
Call #26: October 21, 2024
1. Team updates
@ignaciohagopian and @gballet for @go_ethereum: added around 30 new tests in the execution test spec repo, mostly covering edge cases regarding out of gas execution transactions. (This is relevant for Verkle because if you run out of gas, you might generate a partial witness). Guilluame has been working on speeding up witness generation, as well as the rebase on top of Cancun to get updated metrics.
@jasoriatanishq for @nethermindeth: testing and debugging latest hive tests. Also have been progressing on the Nethermind implementation of the transition.
@lu-pinto and @kt2am1990 for @HyperledgerBesu: Working on gas costs. Currently 2 tests are failing (regarding self-destruct). Also all of the BLOCKHASH tests are failing because the logic for pulling out the BLOCKHASH from the system contract is not yet implemented, but that’s up next. Have also completed some optimizations on the rust-verkle crypto library. And now have a working version of the flatDB based on stem. Next step here is to generate the preimage to be able to run this flatDB with mainnet blocks and compare performance. Lastly, continuing to work on integrating the Constantine crypto library into Besu.
2. Circle STARKs seminar
Matan joined to share some info on an upcoming SNARK-focused seminar he will be leading, which will be open for anyone currently working on stateless. The seminar will be focused on bridging the gaps for upcoming items on the Verge roadmap, in particular exploring the topics of SNARKing Verkle, Circle STARKs, and STARKed binary hash trees (as a potential alternative to Verkle). No prerequisites or math background required for the course. Idea is accessible to lay audience. The seminar will likely be weekly and run for TBD number of weeks.
3. Verkle Metrics
Guillaume shared an updated document which provides a helpful overview of latest Verkle metrics. This is data collected by replaying ~200k historical blocks (around the time of the Shanghai fork). While they don’t provide a perfect prediction for how things will look in the future, it does help give a solid approximation of what to expect.
Few highlights below, and check out the doc for the full report.
Witness size
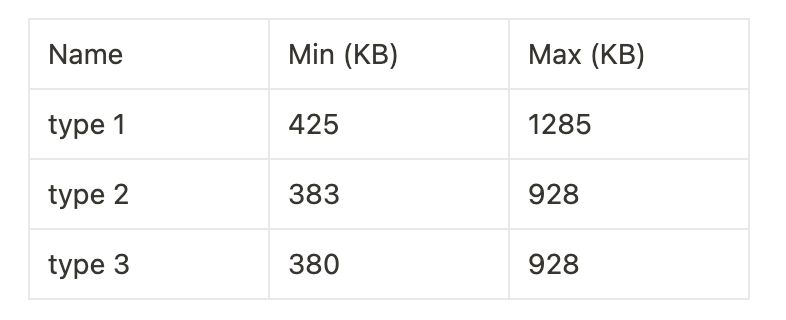
Database
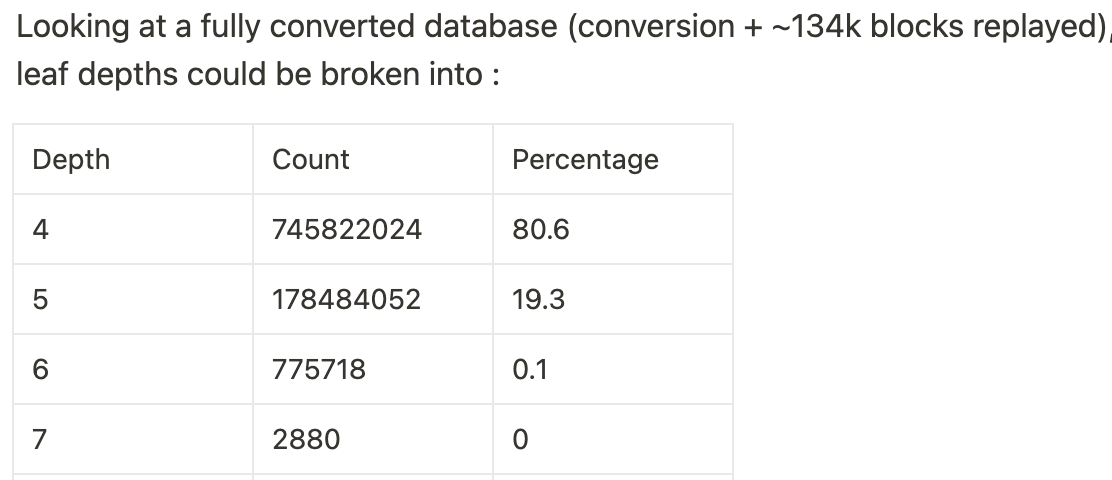
Tree key hashing: comparing Pedersen vs sha256
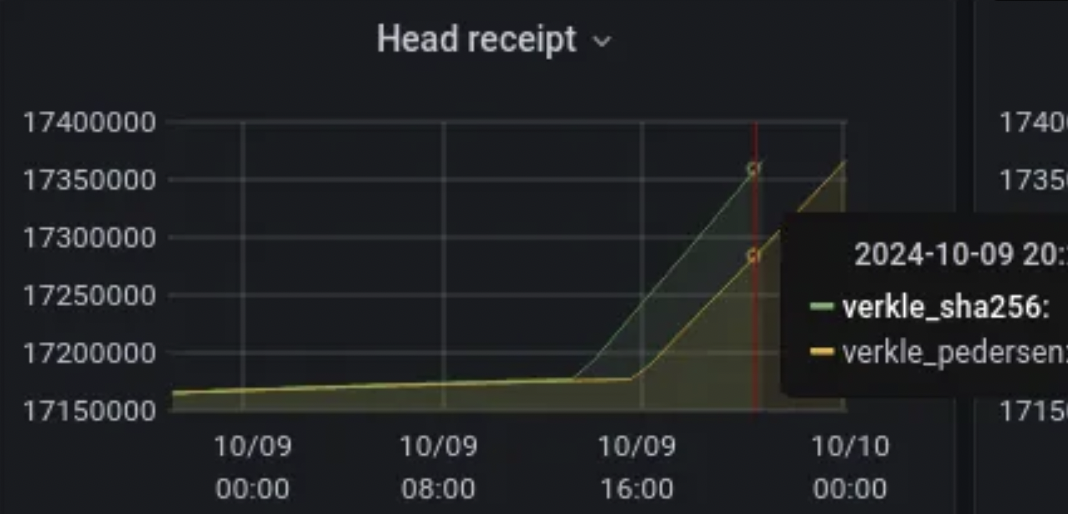
4. Spec Updates
Last up on this week’s call, a few quick points related to gas cost spec:
CREATEgas cost: currently 32,000. But for Verkle, we’ve considered reducing this.- Decision: keep as-is for now.
- How much to charge when doing account creation (e.g. when doing a call and the address does not exist yet). And similar question for
SELFDESTRUCT- Decision: open a convo with research team for further discussion
Call #25: September 23, 2024
1. Team updates
@ignaciohagopian and @gballet for @go_ethereum: just about ready for testnet relaunch. Most PRs merged. Also working on benchmarking. Some updates to the test fields, and fixed some tests around witness checks. Can also run the tests in stateless mode soon, where the witness acts as the prestate source of truth.
@jasoriatanishq for @nethermindeth: no major updates. Working with Ignacio on tests. Will try to run the tests in stateless mode this week 🔥
@kt2am1990 and @lu-pinto for @HyperledgerBesu: last week, working on the flat DB based on stem key. Completed some benchmarking to see impact on SLOAD. Found the perf was quite bad. Working with Kev on some optimizations. Also working on integrating Constantine library into Besu, in order to compare perf. Made some good progress on getting the test fixtures to run. Will get back to finalziing gas costs after.
2. EIP-7702 in Verkle
We quickly went through a PR from Guillaume to update the stateless gas costs EIP in order to support changes coming in 7702. (Current plan is for 7702 to be included in Pectra, & 7702 contains a new type of tx: authorization_list. Info that is used to update some accounts)
TLDR is this updates the gas costs EIP so if you call these functions (EXTCODESIZE, EXTCODEHASH etc), then you also need to touch the CODEHASH_LEAF_KEY. Ping Guillaume with any comments/questions.
3. Partial Witness Charging
Ignacio walked through a few scenarios where a bit more granularity may be needed around gas costs in Verkle. See PR here.
Scenario 1: if you don’t have enough gas to pay for whatever witness charging you have to do, then you don’t actually need to include that in the witness. (e.g. if you do a jump and don’t have enough available to pay, then you wouldn’t include that cold chunk in the witness)
Scenario 2: there are several places in execution where you have to include more than one leaf in the witness. In these cases, Geth was previously always including both leaves. Even if you didn’t have enough gas, it was already added to the witness.
For both scenarios we want to allow for better granularity / partial witness charging.
TLDR: only add things to the witness if you have the available gas for it
4. Testnet-7 Check-in
Ending things with a quick check on testnet readiness. Pari said DevOps should have time to assist later this week. Recommended doing it locally first in case bugs are found, and then once it works locally switch to a public testnet 🥳
Call #24: September 9, 2024
1. Team updates
Gary for @HyperledgerBesu: continuing work on stem-based flat database, and have a working implementation. Will simplify sync for Besu. Also making progress on gas cost changes and witness updates (EIP-4762). And planning on getting back to work on the transition stuff soon.
@ignaciohagopian and @gballet for @go_ethereum: last week, discussed sync with the Geth team, and would like to figure out how performant it is to compute all of the leaves as they are needed (reading SLOAD + building a snapshot based on those leaves). Interested to understand Besu’s performance in this regard. Also completed a bunch of work on the testing framework. Gas costs are ready to go. Should be ready for new testnet in next few days.
@GabRocheleau for @EFJavaScript: continued work to prepare for the upcoming testnet. Running the actual tests this week. Also made some upgrades to the WASM cryptography library so can begin creating proofs, and allows for stateful verkle state manager. Previously could only run blocks statelessly.
@jasoriatanishq for @nethermindeth: mostly been working on getting the Hive test running. Found and fixed a few bugs. One change in the spec around gas costs, and continuing work on the transition. Working on some cryptography improvements as well.
Somnath for @ErigonEth: integrating the gas cost changes and the witness calculation changes. Noticed some issues with the state management, but hopeful can resolve it in next week. Erigon has already started migrating everything to Erigon 3, but current verkle work is based on Erigon 2. Will try to join devnet-7 soon after it launches.
@g11tech for @lodestar_eth: rebasing on latest from lodestar, which should provide a more stable base for testnet because of improved performance.
@techbro_ccoli for the testing team: we have the witness assertions now within the framework when filling tests. Can write a test, and assert that a balance is what you expect. More of a sanity check. Now have similar for witness-specific values. Next step is to optimize how the tests are filled, and improve the transition tool runtime.
2. Devnet Readiness
There’s a couple updates to the specs that are still open. Quickly reviewed with Guillaume 3 PRs to merge in asap for the testnet:
https://github.com/ethereum/EIPs/pull/8867
https://github.com/ethereum/EIPs/pull/8707
https://github.com/ethereum/EIPs/pull/8697
^ Leaving open for comments, but no objections raised during the call on these PRs.
3. Verkle, Binary, & Tree-agnostic development

Quick recap of recent conversations we’ve had around the tradeoffs of Binary vs. Verkle:
This is a topic that has come up often over the past few years, and even going all the way back to 2019/2020 – when @gballet was an author of EIP-3102: an initial proposal to migrate to a binary trie structure.
More recently, as many teams have made strong progress on the ZK proving side, there’s been renewed discussion around whether a ZK-based solution could be ready in a similar timeframe to Verkle (or soon thereafter), and allow us to skip straight to a fully SNARKed L1.
In this scenario, a binary trie structure is arguably preferable, in that it’s a friendlier option to current ZK proving systems, despite Verkle’s advantages in other dimensions (such as smaller tree/proof size and slower state growth). While Verkle is closer to “mainnet ready” today, it’s possible the gap closes over the next 1-2 years.
The challenge and discussion now is mostly centered around how we can optimize forward progress on R&D efforts, solve problems facing users today, while also making sure we properly evaluate other viable/evolving technologies to ensure we land on the best long-term path for the protocol + users.
TLDR:
it’s safe to say we plan on doing a bit more of at least two things over the next ~3-6 months:
(1) evaluate binary: invest meaningful bandwidth into exploring / benchmarking a binary tree structure, while collaborating closely with zk teams. Make sure we understand where we are today in terms of performance, hardware requirements (with which hash function etc.), and where things need to be in order to be viable on L1.
(2) tree-agnostic development: continue building the infrastructure and tooling necessary for statelessness, but lean into a tree-agnostic approach to optimize for reusability. This will give us flexibility to land on the best solution, whether it’s Verkle, Binary, or anything else. In any case, much of what has already been built (e.g. for state migration) will be a valuable and necessary component since it’s unlikely we stick with the current MPT for long.
If you are excited about making progress on statelessness and scaling the L1, you can join the conversation in our biweekly implementers call 🚀
4. Deletions in Verkle
Discussion around whether not having deletions in Verkle will bloat the state. There are also downsides to deletions though, as it may make the conversion process a bit more complicated. TBD on final decision, but no strong objections raised to supporting deletions in Verkle. Recommend watching the recording for anyone interested in better understanding the full picture on this topic.
5. Pectra Impact (7702, EOF, etc.)
Ignacio gave an overview of some work he’s done to better understand the potential impact of EOF on Verkle. He created a draft PR with the changes required. Guillaume also shared some thoughts on things we need to be mindful of with 7702. Namely around making sure that when you add something to the witness, you add the contract that the operation is delegated to instead of the account itself (otherwise the witness will be empty).
6. Verkle Sync
Geth team recently had a discussion on the topic of sync, and came away with a few potential suggestions.
(1) around witness validation: full nodes can validate witnesses and make sure that no extra data is being passed as a way to prevent bloating of the witness. (e.g. flag a block that has too many leaves as invalid). Note: if we do introduce this rule, then we have to make the witness itself part of the block.
(2) snapshot per stem, rather than by hash like it currently is.
(3) how long to save the witness on disk: if we save it for something like a month or so, then it makes it a bit simpler for nodes who have been offline for a short period of time (e.g. 2-3 weeks) to rejoin the network. The tradeoff is it would add around 60GB.
Call #23: August 26, 2024
1. Team updates
@ignaciohagopian and @gballet for @go_ethereum: making solid progress on testing and the upcoming testnet. Managed to get the branch with latest gas schedule working with tests.
@jasoriatanishq for @nethermindeth: have implemented everything for the testnet. Also working on a few cryptography improvements, and a big refactor to implement the transition. Might be able to implement test transition in next few weeks.
@kt2am1990 for @HyperledgerBesu: working on modifying how we save data in the DB, to implement a flat DB based on the stem of the tree. Also working on gas cost implementation and the transition.
@GabRocheleau for @EFJavaScript: ready with all the gas cost updates, likewise just waiting for test vectors to confirm.
Somnath for @ErigonEth: getting caught up with the changes up to the most recent testnet. Had an issue when trying to connect to peers on testnet-6, not getting any replies. Will debug with ops.
@techbro_ccoli for the testing team: have released latest fixtures, can be found here.
2. Testing Verkle overview
Next up, we had a brief presentation from @ignaciohagopian to walk through latest overall progress on the test framework for Verkle. The main branch for the test vectors can be found here in the execution spec tests repo. And to look at existing tests you can find them here in the tests/verkle folder, where all the tests are separated by EIP. Encourage anyone interested to poke around, ask questions, and eventually open up new test cases :)
Ignacio also gave an overview of the changes that were made in geth to support the test framework, how the CI pipeline works, and a summary of all the test fixtures that exist today. The fixtures can be separated into 3 groups:
(1) Verkle-genesis, where everything happens in a post-merkle patricia tree (MPT) world,
(2) overlay-tree, which is running tests with a “frozen” MPT, and doing the block execution in the Verkle tree,
(3) consuming tests from previous forks, to check pre-Verkle execution isn’t broken

3. Testnet readiness check
Next up, we went through and double checked each team’s readiness for the next testnet. Geth, Nethermind, and EthJS are ready as far as we can tell at this point, while Besu is still finishing up gas cost updates.
4. Binary Tree Exploration
Last up, Guillaume shared a presentation which summarizes some recent discussions we’ve had, as there’s been a bit of a renewed push by some in the community to explore binary trees as a potential alternative to Verkle. Some of this push has been motivated by recent progress made in ZK proving performance, and a desire to provide something that is even more zk-friendly than Verkle to help accelerate the move towards an eventual fully SNARK-ified L1.
Highly recommend watching the recording to view Guillaume’s full presentation, but to give a rough TLDR: the main advantage of Verkle (apart from the fact that progress on Verkle is much further along today compared to a binary tree alternative) is that Verkle gives us small proofs (~400kb). And these proofs can enable stateless clients pretty much as soon as we ship Verkle.
On the other hand, the advantages of binary trees is that hashing performance / commitment computation are much faster in general. And are also more compatible with current ZK proving schemes. The other advantage is around quantum resistance, though of course still much debate around timelines for quantum, and there are several other areas of the protocol that will need to be upgraded as part of any post-quantum push.
The good news is: in either case, much of the work we’ve already done with Verkle is reusable in a binary tree design: (1) gas cost changes, (2) the single-tree structure, (3) the conversion & preimage distribution, and (4) (potentially) sync.
What would change with binary trees though include: (1) the proof system, and (2) the cryptography (replacing polynomial commitments/pedersen with hashes)
Call #22: July 29, 2024
1. Team updates
@ignaciohagopian and @gballet for @go_ethereum: working on implementing the fill_cost updates for next testnet. Also did a series of measurements around witness size, and opened an EIP for the state transition. Will share more on this later in the call.
@jasoriatanishq for @nethermindeth: have implemented all the changes discussed for testnet7. Still need to pass the Hive test.
@techbro_ccoli for the testing team: Spencer gave a quick summary of the current tests available for Verkle. At the moment, we only have transition tests, and no state tests. Will work on getting the remaining tests ready for the newest test cases that Ignacio has written, so we can run those prior to cutting the next testnet. Ideally will also soon make it easy for everyone to just run a command to build and test everything. Can find the latest Verkle tests here.
2. SSZ and witness size improvements
@gballet shared a summary of three different approaches we are exploring around the encoding of witnesses. The current spec as-is results in unnecessarily large witnesses, due to some nuance around the handling by SSZ libraries. So we are exploring alternative approaches. Recommend watching the full recording to get all the details. But the tldr is that these alternative approaches look very promising, and should reduce witness size by 50% or more, to where the median witness size will be under 300kb, and the max witness size will be under 1MB. There are some future potential optimizations Guillaume is looking into as well which may reduce witness size by another 50%.
3. Kaustinen updates (testnet #7)
We took a few mins to go through any last minute changes or additions we’d like to include in the next testnet: Kaustinen 7. The first topic was revisiting the verkle proof format, and changing it from SSZ/JSON into an opaque binary format. It’s generally agreed we should do it in the long-run, but still a question of whether to do it for this next testnet. Decision on the call was to wait and not do this in Kaustinen 7.
The next topic on Kaustinen 7 was whether to include the fill_cost updates. Decision on the call was to not include it, because it would slow things down significantly, and require a tricky rebase (merging it with more recent code).
4. EIP for the Verkle state transition
Last up, @ignaciohagopian walked us through a few recent PRs he put up with quick fixes to EIP-7612 and EIP-6800, as well as a new EIP for the actual transition (where we migrate all state from the Merkle Patricia Tree over to the Verkle Tree). This new EIP can be found at EIP-7748.
The main goal of this new EIP is to formalize the state conversion algorithm that is being implemented by clients. (This is the same design that we have discussed for several months, but simply hadn’t been formalized into an EIP). Check out the linked PR for a more detailed explanation, but the short summary is that the state migration involves converting a fixed number of key-values each block (e.g. 10k values) over an extended period of time (e.g. 4 weeks). The number of key-values converted each block can be adjusted up or down, but is currently set to a conservative number to ensure that even modest hardware is able to keep up with the transition. This has already been successfully implemented in Geth, and more clients are following soon behind.
Call #21: July 15, 2024
1. Team updates
@ignaciohagopian and @gballet for @go_ethereum: finishing up document on code chunking gas cost overhead in Verkle. Also working on more test vectors for the state conversion (converting state from Merkle to Verkle). And putting together first draft of the state conversion EIP, to help with coordination and act as the source of truth for test vectors. In addition, Guillaume has been collecting witness size data, preparing for the testnet relaunch, and busy merging more Verkle stuff into Geth so we can have a testnet on top of Dencun.
@DoctZed for @HyperledgerBesu: currently optimizing around storage in the DB, and moving some of the work to background threads. Also finishing up the updates to gas cost schedule.
@techbro_ccoli for testing team: continuing work on the genesis test vectors. Also discussed a bit with Guillaume about making the tests runnable by anyone, so that each client team can check prior to relaunching the next testnet. @techbro_ccoli to put together a document on how to run the tests easily. Can find the tests here: https://github.com/ethereum/execution-spec-tests/releases
2. Testnet readiness
We went through the main items we want to include on the next testnet, to see where client teams are in terms of readiness. Geth is still working through a few items: notably fill_cost and other gas cost updates. Nethermind has implemented everything previously discussed at the client team interop, but still need to run latest test framework to verify. Besu is not yet complete, and need to wrap up some of the DB work they are currently in process of refactoring before finishing up testnet work.
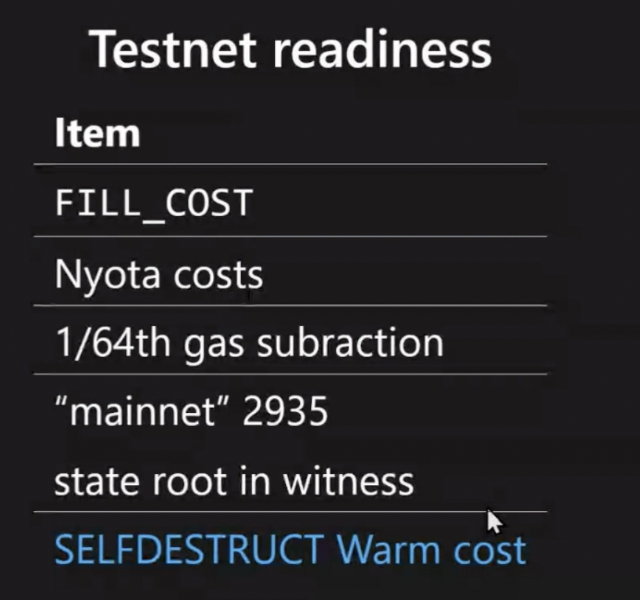
3. Witness size measurements
Next up, Guillaume shared some recent experiments he has been running around witness sizes, as well as some potential optimizations. Tldr: in the current version of the spec we store the state diff in a certain way with the old value and new value as optionals.
The issue with this approach is that very few SSZ libraries support optionals, and due to how other libraries handle this it makes for unnecessarily large witnesses.
So, one proposal to fix this: get rid of optionals by grouping all the suffixes together in an array of bytes, and grouping all the old values and new values likewise in their own lists.

Testing this new approach (vs. the current approach) results in significant reduction in witness size. The current approach has a median witness size of ~700kb. While the new approach has a median witness size of ~400kb. One note: we can further reduce the witness size significantly (possibly another 50%) by removing new_values, which would put witness size closer to 200kb.
Guillaume also shared a 2nd proposal for an optimization which could further reduce witness size. (Still need to implement it to get the numbers). Will come back to this discussion on a future call.
4. Other Misc EIP Updates
Next up, we went through a few updates to EIPs including EIP-6800 and EIP-2935. See the complete list here: https://notes.ethereum.org/@gballet/S1YEC5fOA#/5.
This is mostly relevant for client devs and other implementers, but recommend watching the recording for anyone interested!
5. Code-access Gas Overhead
Last up, @ignaciohagopian walked us through a document he put together, which provides a very helpful analysis of the cost of code chunking in Verkle.
For those not familiar: in order to fully support stateless clients in a post-Verkle world, we will have to add contract code to the tree (in addition to account data and contract storage). This is necessary for clients to statelessly validate blocks. This process of transforming contract bytecode into tree key-values is called “code-chunking”. But code-chunking is not free, and will add some new gas cost overhead which doesn’t exist today in a stateful world.
Ignacio’s document does a great job at summarizing, analyzing, and approximating what these costs will be with Verkle by looking at ~1 million recent mainnet transactions. The TLDR is that, on avg, we should expect around 30% gas cost overhead. The good news is there are several ways we can potentially mitigate this. Importantly, paying this extra cost will unlock stateless clients, which will allow us to significantly raise the gas limit (more than 30%) to more than offset this additional cost. See https://x.com/dankrad/status/1790721271321256214.
Highly recommend watching the recording, and also going through Ignacio’s full document here for anyone curious to learn more: https://hackmd.io/@jsign/verkle-code-mainnet-chunking-analysis.
Devnets
As a way to test this very complex change to the protocol, devnets are frequently run to assess the code quality and ensure that every client implementation agrees on the spec. This has helped identify many corner cases of the specification as well as find many issues in client implementations.
This typically includes:
- A faucet so that developers can obtain tokens to deploy their contracts on the devnet.
- A block explorer, which displays witness content.
- A witness explorer, which is a tool that we can use to look at the produced witnesses as well as figure out the specific gas costs related to Stateless Ethereum.
- The specification sheets that list the peculiarities of this devnet.
- Various RPC endpoints to interact with the devnet.
- A forkmon instance to check that all the nodes on the devnet agree on what the head block is.
- Information about the genesis block and other network configuration items that any node that wants to join the devnet will need.
There’s currently an active devnet-7 which can be used for core developers and users to make progress in the implementations of proposed protocol changes. The latest devnet is always available at the address kaustinen-testnet.ethpandaops.io.
Joining the devnet
For execution layer developers implementing stateless EIPs or anybody interested in just following the devnet to use their node as a private RPC endpoint, we recommend using the tool called lodestar-quickstart.
Make sure that docker is installed on your system. Sync the repository for the first time:
$ git clone https://github.com/ChainSafe/lodestar-quickstart # sync repository
$ cd lodestar-quickstart
Then, prepare the devnet configuration directory and launch the sync (repeat these steps each time):
$ rm -rf k7data # don't forget to use these commands between runs
$ ./setup.sh --network kaustinen7 --dataDir k7data
Some of these commands might require sudo or super-user privileges.
This will start a container for the consensus layer clients and a container for the execution layer client. If you want to test your execution layer client, just ask lodestar-quickstart to only start the CL:
$ rm -rf k7data # don't forget to use these commands between runs
$ ./setup.sh --network kaustinen7 --dataDir k7data --justCL
Then, start the EL manually on the side. For example, with geth:
$ go run ./cmd/geth --cache.preimages init \
path/to/lodestar-quickstart/k7data/network-configs/gen-devnet-7/metadata/genesis.json
$ go run ./cmd/geth --syncmode=full --bootnodes \
"enode://548ff025abb1522c5257f50765abd21754b7ea7159a176a9b96c738ee6456fc378a11c09a62d55d92684634cd32a9cad498f5649256caf693dab77f961a169f6@167.235.68.89:30303" \
--authrpc.secret=path/to/lodestar-quickstart/k7data/jwtsecret
Testing
Ethereum stateless protocol changes cut deep into the protocol since it must simultaneously change many angles, such as the state tree, EVM gas costs, and opcode functioning.
Execution spec tests
One strategy for testing is using devnets, where multiple clients join and can check if they reach a consensus on executing automatically generated transactions or letting users experiment with the new features. While they’re very useful, it’s pretty costly to spin up a devnet, mainly in the early to mid stages of protocol development for clients — mainly on the coordination front.
A more efficient approach is creating a comprehensive test suite runnable by every client. Clients can efficiently run these test suites while they’re in development, both manually and in CIs. Since this doesn’t require a devnet, there’s no required coordination or overheads, allowing us to make progress faster. Moreover, they allow us to precisely describe corner case scenarios, which would be hard to replicate on every development spin-up.
There’s currently an active branch in execution-spec-tests, which contains tests for:
- EIP-4762
- EIP-6800
- EIP-7709
- EIP-7612
The current test suite contains ~200 test fixtures, which have uncovered more than 15 consensus bugs throughout many EL clients, usually in intricate corner cases. It is still far from perfect, and there’s always ongoing effort to improve it. For example, if any bug is detected in a devnet, adding it as a new test is important.
Note that filling tests for such deep protocol changes involved more than creating the tests; it also involved making big changes in the testing framework and Geth’s evm t8n filling tools. This effort was made collaboratively between the Stateless Consensus and the STEEL teams at the EF.
Filling & running tests
The execution spec test documentation is an excellent resource for understanding the overall process. Next, we’ll provide concrete steps referencing which are the right branches to be used to fill the test properly:
- Install the required prerequisites to use the testing framework.
- Pull the main branch from this repo.
- Run
go build -o evm ./cmd/evm - Save the generated binary in
PATH_A
- Run
- Pull the
verkle/mainbranch from the execution-spec-tests repo- Run
uv run fill --fork Verkle -v -m blockchain_test -n auto --evm-bin=<PATH_A>to fill the tests. You can use whatever extra flags are described in the testing framework documentation to filter fillings.
- Run
- In the
fixturesfolder, you’ll find the generated fixtures.
The command for running the test depends on your EL client. For example, in Geth, you should go run ./cmd/blocktest <json fixture path>.
CI
In the Geth branch used for stateless development, there are GitHub Actions workflows:
These are run on every new PR, so there’s quick feedback if a new feature or bug fix has a regression — they can also be helpful for other EL teams to include in their pipelines. You can also semi-derive the steps mentioned in the Filling tests section by reading the CI steps.
Contributing
Stateless Ethereum is an open-source initiative pushing the boundaries of Ethereum scalability and usability. We welcome contributors from all backgrounds—whether you’re a blockchain researcher, cryptography expert, protocol developer, or just passionate about decentralized technology.
How to Get Involved
- Help with the documentation
- Read this book and create a pull request to add any information you think is missing.
- Join the Discussion
- Use our devnets
- Deploy your contracts on the devnet.
- Run your own node.
- Pick an issue in one of our repositories
- Look for issues labeled “Good First Issue” or “Help Wanted” in our GitHub.
- If you’re unsure where to start, open a discussion—we’d love to help!
- Implement our specs in various clients
- Not all clients implement all features, so check for issues in their repositories with the
verkleorstatelesstags/branches. - Submit a pull request (PR) and request a review from the maintainers.
- Not all clients implement all features, so check for issues in their repositories with the
- Review & Improve
- Review open PRs, suggest improvements, and help refine the implementation.
- Contribute to documentation and educational resources.
- Review our use cases or add your own
- Look at the list of our use cases and give us some feedback.
- Build your own demos and share them with us.
- Help spread the gospel of stateless
- Share our talks and articles.
- Create some learning resources of your own!
Every contribution—big or small—helps bring stateless Ethereum closer to reality. 🚀
Advanced topics
This section gathers all developments topics that are of interest to people implementing stateless in their clients or application.
Testing the Holesky shadowfork with geth’s devmode
Prerequisites
- Geth’s kaustinen-with-shapella branch
- Download the pre-pectra holesky database and unpack it:
> tar --zstd -xf snapshot_holesky.tar.zstd
This will create a directory called geth in your current directory. Save the full path to this directory in GETH_DIR.
Make sure to keep a copy of the tar file, as the unpacked database will be written to and the transition will be irreversibly marked as finished.
- Run the conversion:
> go run ./cmd/geth --datadir=$GETH_DIR --dev --dev.period=2 --override.cancun=1900000000 --override.verkle=(date "+%s") --override.overlay-stride=10000
Note that:
--dev.period=2causes a block to be created every 2s, which allows for faster conversion.--override.cancun=1900000000is meant to set Cancun far out in the future, as this branch doesn’t support Cancun. When Pectra ships,--override.pectra=will also need to be specified far out in the future (unless the rebase finally completes).--override.verkle=(date "+%s")is meant to set the Verkle fork to happen at the current time, so that the next block will trigger the Verkle conversion.--override.overlay-stride=10000sets how many leaves get converted per block. The recommended value is 10k but higher numbers mean the conversion will complete faster.
- Check the conversion status by RPC:
> curl -s -X POST -H "Content-Type: application/json" -d '{ "id": 7, "jsonrpc": "2.0", "method": "debug_conversionStatus", "params": ["latest"]}' http://localhost:8545 | jq '.result.ended'